We are roughly a decade removed from the beginnings of the modern machine learning (ML) platform, inspired largely by the growing ecosystem of open-source Python-based technologies for data scientists. It’s a good time for us to reflect back upon the progress that has been made, highlight the major problems enterprises have with existing ML platforms, and discuss what the next generation of platforms will be like. As we’ll discuss, we believe the next disruption in the ML platform market will be the growth of data-first AI platforms.
Essential Components for an ML Solution
It is sometimes easy to forget now (or, tragically, maybe it’s all too real for some), but there was once a time when building machine learning models required a substantial amount of work. In days not too far gone, this would involve implementing your own algorithms, writing tons of code in the process, and hoping you make no crucial errors in translating academic work into a functional library. Now that we have things like scikit-learn, XGBoost, and Tensorflow/PyTorch, a large obstacle has been removed and it’s possible for non-experts to create models with a smaller amount of domain knowledge and coding experience, and perhaps get initial results back in hours. In the process, it can sometimes be easy to forget what is at the essence of a ML solution. Were we inclined to attempt to solve a ML problem from scratch, what would we need? I’ve long believed that there are four key pieces to any ML solution:
- Data: Training data is essential for any ML algorithm.
- Code: Pick your library of choice, but some code will be required to use it.
- Environment: We need somewhere to run the code.
- Model: The thing we’ll use to make predictions.
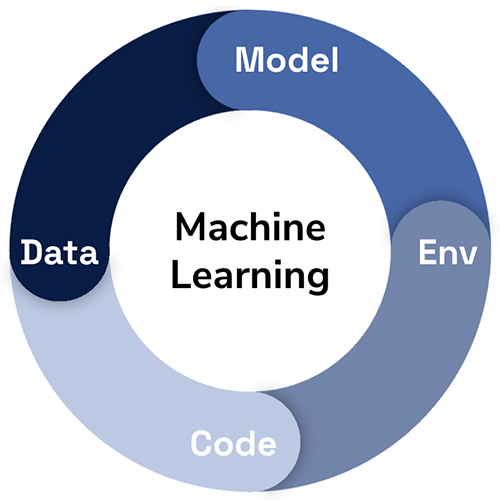
The resulting outputs are predictions, which inevitably is what the business is interested in, but there’s non-trivial effort to get there. I bring this up because I’d like to propose it as a way to view the different generations of ML platforms, based upon which of the four elements listed above they focus on:
- Generation 1 is code- and environment-based: The focus is on writing code, collaborating, and making it easy to execute that code.
- Generation 2 is model-based: The focus is on quickly creating and tracking experiments, as well as deploying, monitoring, and understanding models.
- Generation 3 is data-based: The focus is on the construction of features and labels – the truly unique aspect of most use cases – and automation of the rest of the ML workflow.
Platforms can change greatly based upon their focus, as we’ll see below. The one that is right for your organization largely depends on what your goals are: do you need a platform that streamlines the development lifecycle for research-oriented data scientists (Gen 1), or something that helps your business execute AI use cases as quickly as possible with minimal risk (Gen 3)?
Generation 1: Collaborative Data Science
The modern take on the ML platform began to take shape in the late 2000s as an ecosystem of Python open-source libraries were emerging that made the task of developing data science relatively easy. Packages like NumPy (2006), pandas (2008), and scikit-learn (2007) made transforming and modeling data in Python much easier than it previously was, and, combined with tools like matplotlib (2003) and IPython (2001), newly minted data scientists could spin up a local development environment fairly quickly and readily have a multitude of tools at their disposal. Many early data practitioners came from the academic world and were previously accustomed to notebook-oriented tools like Mathematica and Maple, so it was no surprise that the release of IPython Notebooks in 2011 (later renamed to Jupyter Notebooks in 2015) came with much fanfare (Although we’ll take a Python-centric approach for this article, it’s worth noting that RStudio was also released in 2011). By this time, Python package and environment management were also getting easier thanks to Pypa (which maintains tools like virtualenv and pip); and a few years later data scientists got more powerful modeling tools with XGBoost (2014), TensorFlow (2015), and PyTorch (2016). All the pieces were really falling into place for Python data professionals.

Image: jupyter.org
Notebooks were, and continue to be, one of the main tools that data scientists use on a day-to-day basis. Love them or hate them, they have entrenched themselves in the ML landscape in a way that no other editor technology has. However, as great as they may be, as real companies began adopting notebooks into their technology stacks, they inevitably discovered many gaps (this list is not exhaustive), such as:
- Sharing work and collaborating with peers
- Building a valid environment to run someone else’s notebook
- Getting access to the right infrastructure to run code
- Scheduling notebooks
- Enforcing coding standards
High-tech companies who adopted notebooks early have likely built some sort of bespoke solution that tackles the above challenges (and maybe more!). For the rest, software vendors began to emerge offering “collaborative data science” tools. These tools were built for data scientists: they revolve around notebooks and try to reduce the friction in collaborating and running code at the enterprise level. If we refer back to our original essential components of machine learning, these tools are squarely focused on code and environment. Contemporary solutions are cloud-based and run in containers, abstracting away even more complexity from the data scientist. Generally speaking, they tend to be good at what they do: providing a nice development sandbox for data scientists to explore and collaborate.

Over the years, however, these tools have demonstrated that they fall short in several areas (again, not exhaustive):
- Lack of Operational Model: By making the platform as general and flexible as possible, it becomes more difficult to automate common tasks.
- Difficult Path to Production: Notebooks are the core resource for this platform, but they are notoriously difficult to rely upon for production work and are greatly error-prone.
- Data Scientist-Focused: Code-based approach is great for data scientists, but it means other users in your organization will get little value out. Even the majority of people you pay to code (software developers) generally dislike notebooks.
- Encourage Pipeline Jungles: The manual nature of the platform means that any production work is going to necessitate a complex rig of data and API pipelines to ensure that things actually work.
- Harder tasks are “exercises left to the reader”: Feature Engineering, Feature Store, Model Deployment & Monitoring, all of this is either done manually or externally.
Although Gen 1 ML platforms have their use in development cycles, time has proven them to be poor systems for production work. I believe that most of the negative press concerning ML being a notoriously difficult field to operationalize is due to the fault of Gen 1 platforms. Notebooks can be great to prototype out a new, difficult use case, but they should quickly be discarded as ideas mature in order to focus on more robust systems. As such, they are generally not a good starting point for creating a production ML system.
Generation 2: Model-Based Point Solutions
Around the time when data science leaders became frustrated with notebook-based platforms, either built in-house or vendor-acquired, lots of people started talking about the “data science workflow” or Machine Learning Development Life Cycle (MLDLC). The point was to develop a framework akin to the Software Development Life Cycle, which is pretty standard in software development groups and helps guide that team from development into production. Such a thing was/is sorely needed in ML to help struggling teams put the pieces together in order to conceptualize a proper ML production strategy.
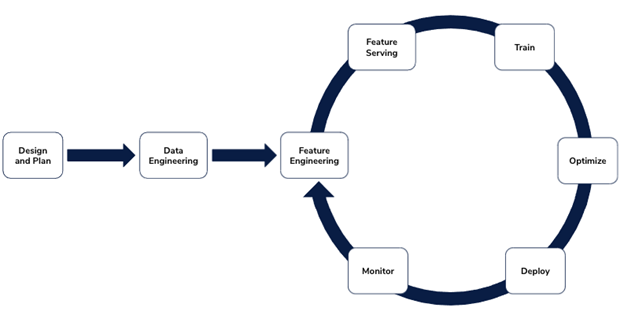
Image: Continual
As we discussed, collaborative data science tools leave many gaps in the path to production, and the MLDLC really highlights this. It will primarily be useful for the early stages of this cycle: around feature engineering and model training. For the rest of the cycle, we’ll need to find other tools.
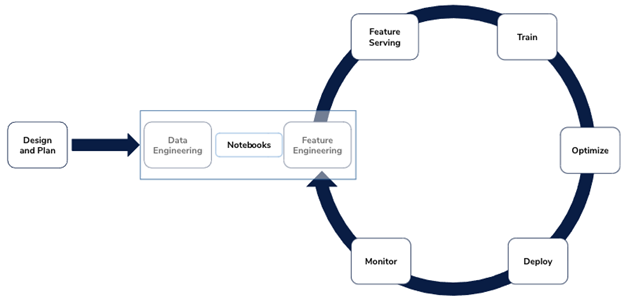
Image: Continual
Luckily, new tools were already on the rise: AutoML tools and experimentation trackers for model training, MLOps tools for model deployment and monitoring, explainable AI Tools (XAI) for model insights, and pipeline tools for end-to-end automation. Interestingly, feature store tools have only really begun to make an appearance in the last couple of years, but we’ll discuss those more in Gen 3. In any case, with enough dedication and elbow grease (or cash), you can cover up all the boxes in the MLDLC and feel content that you’ve built a robust ML platform.
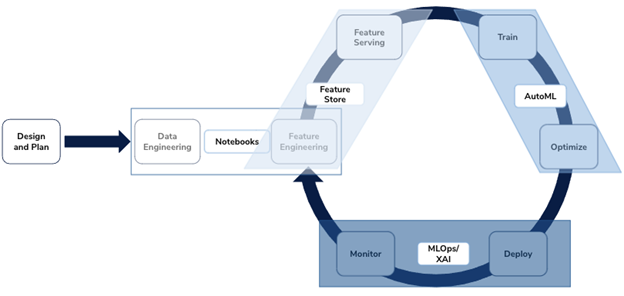
Image: Continual
All these tools solve a specific problem in the MLDLC, and they all focus on models, not code. This represented a pretty big shift in thinking about the ML platform. Instead of expecting data scientists to solve all problems from scratch via coding, perhaps a more reasonable approach is to simply give them tools that help automate various parts of their workflow and make them more productive. Many data science leaders realize that their teams are primarily using algorithms “off the shelf”, so let’s focus on automating the less difficult parts of this process and see if we can arrange the jigsaw pieces into some kind of coherent production process.
This isn’t to say that everyone welcomes these tools with open arms. AutoML, in particular, can be met with a backlash due to data scientists either not trusting the results of the process, or perhaps feeling threatened by its presence. The former is a great case for adopting XAI in step with AutoML, and the latter is something that I believe fades over time as data scientists realize that it’s not competing with them, but rather something they can use to get better and faster results for the business. Nothing should be trusted without scrutiny, but AutoML can be a great tool for automating and templating what is likely going to become a very tedious process as you work through use case after use case.
On the surface, all these model-based point solutions look great. Collect them all like Pokémon and you’ve completed the MLDLC.
However, cobbling together point solutions is also not without its pitfalls:
- Integration Hell: To execute a simple use case, the ML-part of the solution requires four or more different tools. Good luck troubleshooting when something breaks.
- Pipeline Jungles Still Exist: And they’re arguably much worse than they were in Gen 1. You now have your original pipelines going into the ML platform, as well as several more between all your new tools.
- Isolated from Data Plane: These tools are all model-focused and operate on models, not data. You’ll still need a tool like a Gen 1 collaborative notebook to handle any data work that needs to be done, as these don’t provide those capabilities.
- Production is a Complex Web of API/SDK Acrobatics: A realistic production scenario in Gen 2 is: writing a script that generates training data (probably written from a notebook), passing the resulting Dataframe into your AutoML framework via API or SDK, passing the resulting model into your MLOps tool via API or SDK, and then running it through your XAI framework (if you even have one) to generate insights. How do you score new data? Similarly, write another script that leverages more APIs. Run all of this in something like Airflow, or maybe your Gen 1 platform has a scheduler function.
- Harder tasks are “exercises left to the reader”: Feature Engineering, Feature Store, Entity Relationship Mapping, etc… You’re still doing a decent amount of work elsewhere.
- Team of experts required: These tools love to claim that since they are automating parts of the process, they “democratize ML” to make it easy for anybody to self-serve. However, I’ve yet to really find one that places business context first and doesn’t require a team of K8s/cloud engineers, machine learning engineers, and data scientists to operate.
It’s worth noting that Gen 2 platforms have already evolved: more established vendors have either been iterating on new products or acquiring startups to expand offerings. Instead of buying multiple point solutions from multiple vendors, you may be able to buy them all from the same vendor, conveniently dubbed “Enterprise AI”. Unfortunately, what has resulted doesn’t adequately resolve any of the issues listed above, except maybe making integrations slightly less painful (but this is not a given, buyer beware). The main benefit is really just that you can buy all your shiny toys from the same vendor, and when you start working with the tech out of the box you quickly realize that you’re back to square one trying to rig up your own production process across products that share little in common except the name brand.
Don’t confuse this with a Gen 3 approach. There must be a better way.
Generation 3: Declarative Data-First AI
What really is a machine learning model? If we look at it abstractly, it takes data as input and spits out predictions and hopefully also model insights so we can evaluate how well the model is doing. If you accept this as your paradigm for machine learning, it becomes obvious that your ML platform needs to be data-focused. Gen 1 and Gen 2 are unnecessarily concerned with what is happening inside that model, as a result, it becomes nearly impossible for the average company to string together a dependable production process. But, with a data-first approach, this is actually attainable.

To the credit of the Gen 1 and Gen 2 approaches, Gen 3 wouldn’t exist without them. Both because it builds upon some of the concepts they established, and without people struggling to actually operationalize ML with Gen 1 and Gen 2 tools, it likely never would have come about. At the heart of the data-first approach is the idea that AI has advanced enough that you should be able to simply provide a set of training data to your platform, along with a small amount of metadata or configuration, and the platform will be able to create and deploy your use case into production in hours. No coding is necessary. No pipelining. No struggling with DevOps tools as a data scientist. Operationalizing this workflow couldn’t be easier.
How is this possible? There are three core ingredients:
- Feature Store: Register your features and relationships. Automate feature engineering. Collaborate with peers so you don’t have to recreate the wheel every time you need to transform data. Let the feature store figure out how to serve data for training and inference.
- Declarative AI Engine: Raise the level of abstraction and automate building models and generating predictions. Allow power users to customize the experience via configuration.
- Continual MLOps and XAI: Recognize that the world isn’t static. Automate model deployment and promotion. Automate generating model insights. Allow data scientists to act as gatekeepers that review and approve work but put the rest on autopilot.
If you want to see what this looks like in practice, you can try the declarative data-first AI platform we are building at Continual. It sits on top of your cloud data warehouse and continually builds predictive models that never stop learning from your data. Users can interact with the system via CLI, SDK, or UI, but production use is easily operationalized via simple declarative CLI commands.
We’re not the only ones who are thinking about ML in a data-first approach. This idea has been kicking around in FAANG companies for several years, such as Apple’s Overton and Trinity and Uber’s Ludwig. A recent article on Declarative Machine Learning Systems provides an excellent summary of these efforts. Andrew Ng recently riffed on data-centric AI as has Andrej Karpathy from Tesla. We expect that many more are on their way. We also believe that declarative data-first AI is an essential part of the modern data stack, which promises to reduce the complexity of running a data platform in the cloud.
Data-first AI is an exciting new concept that has the potential to drastically simplify operational AI and help enterprises drive business impact from AI/ML. To highlight a few important consequences of data-first AI:
- Reliable path to production: Simplify production ML via a well-defined operational workflow.
- End-to-End Platform: Accelerate time to value by reducing integration tasks and pipeline jungles.
- Democratization of AI: Provide a system so easy that all data professionals can use it. Guard rails allow data scientists to control the process.
- Accelerate Use Case Adoption: Set up production workflows in days, not weeks or months. Manage more production use cares with less resources.
- Reduce Costs: Buy less stuff and lower the cost of maintenance.
Although we believe data-first platforms will arise to be the predominant ML platforms for everyday AI, they are not without their limits. For truly cutting-edge AI research, there’s probably nothing that can get around the fact that manual work will be needed. This may not be a large concern outside the most technical of companies, but it helps to have a development-focused tool available for such times. We believe that the data-first platform is great at solving 95% of the known ML problems out there, and the other 5% may require more TLC. However, we think it’s a monumental improvement to enable 95% of your use cases to be handled by data engineers/analysts with some oversight by a data scientist, and allow the data science team to focus more on the difficult 5% of problems. To do this, they need a stellar system that automates everything and lets them manage and maintain workflow with little intervention required: ala a data-first platform.
What Tool is Right For Your Team?
We’ve covered a lot of ground in this article and discussed a lot of tooling options. At times, the ML/AI tooling landscape can feel overwhelming. The data-first approach to AI disrupts many preconceived notions and its power is best seen to be believed. At Continual, we’re strong believers that ML/AI solutions should be evaluated using your real world use cases. With many solutions, this can take weeks or months and exposes hype from reality. At Continual, our goal is to enable you to deliver your first production use cases in a day. That’s the power of a declarative data-first approach to AI that integrates natively with your cloud data warehouse. If this sounds intriguing, register for our upcoming webinar or reach out to us for a demo so you can experience it for yourself.
The post Is Data-First AI the Next Big Thing? appeared first on Datanami.










0 Commentaires