Faced with an ongoing data generation explosion that refuses to quit, organizations are coming to grips with the realization that data silos will be a fixture in their IT estates for the foreseeable future. One design pattern that’s positioned to help these organizations grapple with all that distributed data is the data mesh, which appears poised to spread its wings in the new year.
The data mesh concept, as we have covered several times in these pages, is an architectural design principle that was first put to paper by Zhamak Dehghani, the director of next tech incubation at Thoughtworks North America in 2019. Over the past two years, the idea has garnered significant momentum among organizations trying to cope with the enormous growth of data, much of it unstructured.
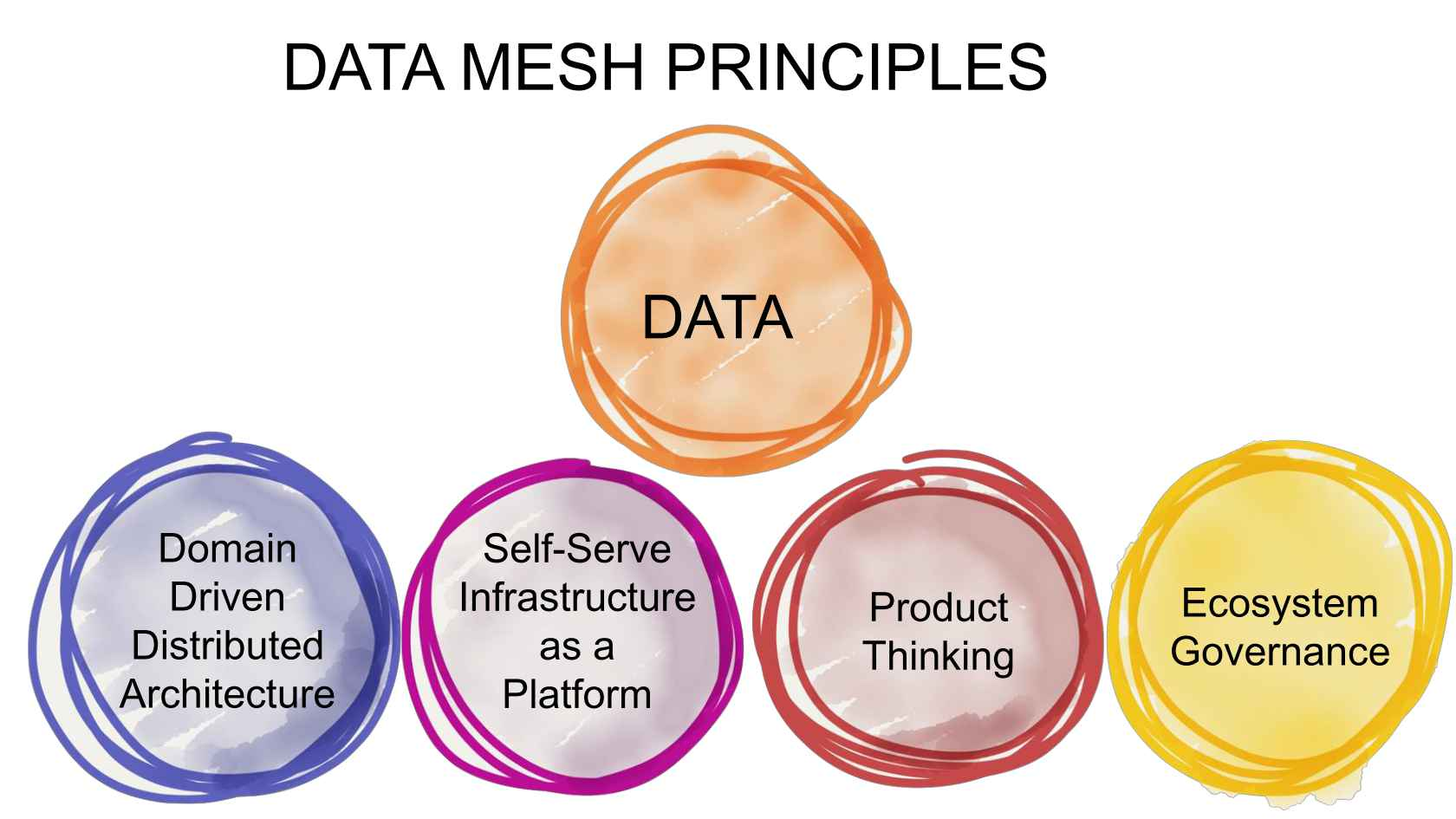
Instead of trying to unify data storage and management, which is not practical for enterprises in the exabyte era, Dehghani realized that organizations are better off setting a series of guiding principles to help various teams work with data in an efficiency and effective manner. The data mesh architecture that she devised was marked by four main characteristics, including: domain-oriented decentralized data ownership and architecture; data-as-a-product development; the rise self-serve data infrastructure platforms; and federated computational governance.
This approach is gaining traction among big companies with far-flung operations. One backer of the data mesh approach is Collibra, the developer of data governance tools. According to Collibra co-founder and CEO Felix Van de Maele, the data mesh approach is the right one for enterprises.
(Image courtesy Zhamak Dehghani)
“We are big believer in data mesh,” Van de Maele told Datanami in an interview last month. “We had Zhamak [Dehghani] be part of our keynote at our most recent Data Citizen Conference earlier this year.”
There’s no longer a debate over whether data can be effectively centralized, Van de Maele said, and that is helping to drive interest in data mesh.
“We have to embrace the fact that, to do data well at scale, it will need to be distributed,” he says. “You can’t centralize. We’ve been trying for 30 years to move all data to one place. That’s never going to work, so you have to accept that it’s going to be fragmented.”
One aspect of data meshes that resonates with Collibra is the focus on empowering individual teams to do more with data, Van de Maele says.
“From an organization perspective, you need to drive ownership in these small teams, leveraging some of the best practices we see from a DevOps perceive being applied to data as well. That’s how it scales,” he says. “And so we’re fully on board on that.”
Decentralized governance has been baked into the Collibra platform since the first bits of the first product were laid down a decade ago. “The way we architected the product 10 years ago, we have concepts like communities and domains and federation and governance models,” Van de Maele says. “We were a big believer already you can’t do governance purely centralized. With a data mesh, you drive more ownership and accountability to the edges, if you will, to the different teams, which is great.”
When groups of data teams are working indpeendnetly, it becomes more important to have a centralized glossary because it provides a common language for the teams to communicate, he says. “We’re big believers from a technical perspective, infrastructure perspective, and an organizational perspective, in the kind of distributed, domain-centric nature of a data mesh,” Van de Maele says.
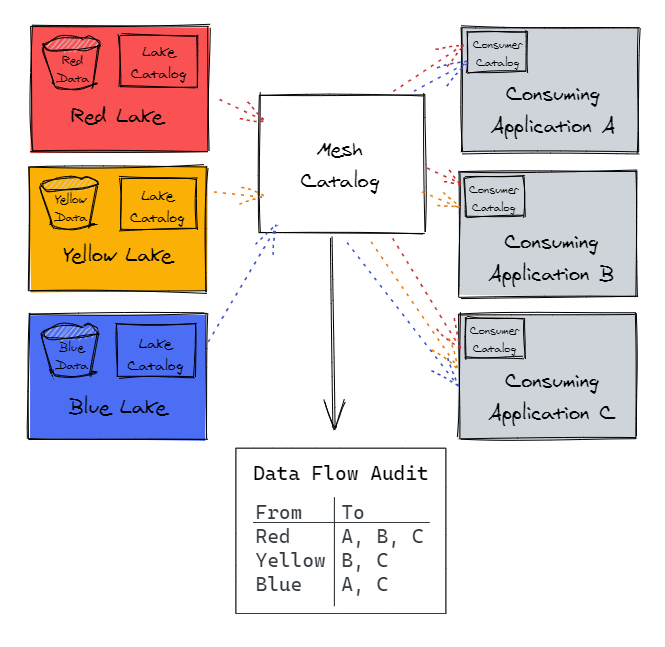
JP Morgan built a data mesh on AWS to enable disparate data teams to work with data in a federated manner (Image source: AWS)
Dan DeMers, the CEO of Cinchy, sees parallels between the data mesh concept and the dataware platform, which seeks to free data from being tied to applications.
“[Dataware] definitely borrows concepts from the data mesh,” DeMers says. “The data mesh approach is that largely focused on the analytical plane and kind of being the anti-data lake to basically decompose the monolith into a federated architecture that organizes data as a product and definitely that holds true in a dataware paradigm. The difference, though, is it doesn’t stop at the analytical plane. It extends even into the operational plane.”
Another believer in the data mesh is Ravi Shankar, the senior vice president and chief marketing officer with CMO at data virtualization provider Denodo. Shankar says that, in 2022, data mesh architectures will become more enticing.
“As organizations grow in size and complexity, central data teams are forced to deal with a wide array of functional units and associated data consumers,” Shankar wrote in his 2022 predictions piece. “This makes it difficult to understand the data requirements for all cross functional teams and offer the right set of data products to their consumers. Data mesh is a new decentralized data architecture approach for data analytics that aims to remove bottlenecks and take data decisions closer to those who understand the data.”
By the way, Shankar is also a believer in data fabrics, which is a related concept that also seeks to find a path forward through the morass of massive distributed data, but one that provides more technological linking of the variety of data management products that organizations need, including ETL, data quality, data lineage, data catalog, and related tools.
Shankar predicts that data and analytics organizations will adopt data fabrics in 2022 to help automate many of the data exploration, ingestion, integration, and preparation tasks. For more information on the difference between data fabrics and data meshes, see the first story under the “Related Items” section below.
Related Items:
Data Mesh Vs. Data Fabric: Understanding the Differences
Starburst Backs Data Mesh Architecture
The Data Mesh Emerges In Pursuit of Data Harmony
The post Data Meshes Set to Spread in 2022 appeared first on Datanami.













0 Commentaires