Data lakes are great in theory, but their application in the real world often leaves the user wanting more. A data mesh is one approach to cleaning up chaos left by data lakes and the resulting swing back to data decentralization. A related technique prospective data mesh users may want to check out is machine learning-powered data mastering, according to a new 451 Research report sponsored by Tamar.
While data lakes have the scale necessary to provide a central repository to store today’s big data sets, they represent a step backwards in terms of the data management and governance previously enforced with data warehouses. As a result, many data lakes–whether implemented via on-prem Hadoop clusters or object storage running in the cloud–turned into data swamps, with lots of data of questionable lineage, quality, and value. As a result, many data teams have simply gone back to housing their own data in individual silos, which brings invites even more data management challenges.
“For years, data lakes held the promise of taming data chaos. Many organizations dumped their ever-growing body of data into a data lake with the hope that having all their data in one place will help bring order to it,” Tamr Co-Founder and CEO Andy Palmer says. “But data lakes are overhyped and often lack proper governance. And without clean, curated data, they simply do not work. That’s why many organizations who implemented data lakes are realizing that what they actually have is a data swamp.”

Does your data lake resemble a data swamp? (Photobank gallery/Shutterstock)
One of the better ideas hatched in response to the wild swings we’ve experienced between huge, anything-goes data lakes and the proliferation of data silos is the data mesh. First conceived by Zhamak Dehghani, a Datanami 2022 Person to Watch, a data mesh is a socio-technological concept designed to unleash the creativity of individual teams to build data products in somewhat autonomous manner, while abiding by common data governance principles and using federated query techniques.
Data mesh represents a new path forward that sought to solve some of the data management and access problems that exist with data warehouses and data lakes. Dehghani elucidated four main components of the data mesh, including distributed domain-driven architectures, self-service platform design, data-as-a-product thinking, and data governance. When implemented together, a data mesh can enable teams to access their own pool of domain-specific data, but do so in a federated approach that doesn’t compromise on manageability and governance at the enterprise level.
There’s a lot of room for other technologies under the data mesh umbrella. In its report titled “Data Mastering Holds Promise as Underpinning Technology for Data Mesh,” 451 Research makes the argument that machine learning-powered data mastering can be one of the key technologies to help make data mesh a success.
“The federated method associated with data mesh seeks to break down functional data silos,” the 451 Research report reads. “Challenges remain, however. If data has not been mastered in some way to create universal and persistent IDs for key entities, the federated queries associated with data mesh will likely be very difficult, or will create even more silos.”
(Source: 451 Research)
Data mastering–or the process of taking new records and linking them to pre-existing master records that have already been vetted–was one of the important data quality steps that enterprises traditionally did as part of loading their data warehouses. However, master data management (MDM) largely fell by the wayside as the pace of data creation picked up and the “schema upon read” approach of the data lake took hold.
Tamr, which sponsored the 451 Research report, is one of the software vendors trying to bring MDM back and make it relevant in the big data world. The company, which was co-founded by Turing Award winner Michael Stonebraker, accepts that relying on humans alone to power MDM isn’t feasible. Neither is a rules-based approach. But backed by the pattern-matching and anomaly-spotting power of machine learning, MDM can provide that critical data quality step that’s needed in today’s big data world without becoming another bottleneck in the process.
The authors of the 451 Research report see ML-powered MDM as an important component in a data mesh, too.
“Enterprise data needs to be cleansed and standardized for the data mesh concept to work at its full potential,” the 451 Research authors write. “Waiting to standardize and cleanse data very near the point of data consumption likely burdens talent and technical resources that are already stretched thin. Consistent data mastering can form a foundational layer to provide standardized keys for data so that federated query is possible.”
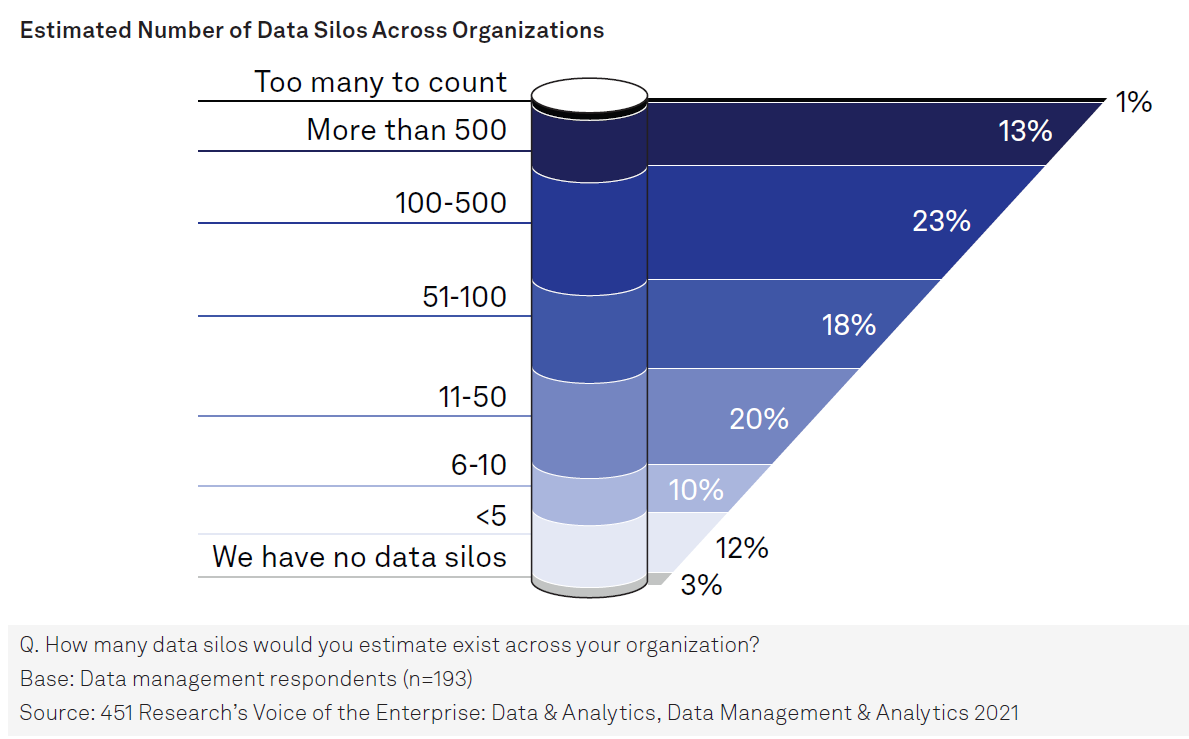
It’s no secret that companies are drowning in data. According to a 451 Research “Voice of the Enterprise” survey, nearly 40% of enterprises have 100 data silos or more, with 1% having “too many to count.” The notion that all data will live in the lake is not feasible, particularly for transactional systems that need high-speed access to read and write data, but also for specialized analytic use cases. The existence of data silos is just a reality that companies must face.
451 Research says the data mesh approach, augmented by data mastering, can give companies the tools they need to gin a more integrated and consistent view of data resources.
“Data mastering can serve as both a complement and augmenter to these efforts, by providing standardized keys for data that can be understood across systems and domains,” the 451 Research authors write. “Data mastering can act as a foundational way to create useful mappings between data identifiers across the organization, aiding in data mesh strategy.”
Related Items:
How ML-Based Data Mastering Saves Millions for Clinical Trial Business
Data Mesh Vs. Data Fabric: Understanding the Differences
The post Mastering the Mesh: Finding Clarity in the Data Lake appeared first on Datanami.











0 Commentaires