Companies that find themselves unable to get answers out of traditional analytical databases quickly enough to satisfy their performance requirements may want to check out an emerging class of real-time analytical databases. As one of the leading members of this new class, Apache Druid is finding followers among the most sophisticated clients, including Salesforce and Confluent.
Cloud data warehouses like Google Big Query, Snowflake, and Amazon Redshift have transformed the economics of big data storage and ushered in a new era of advanced analytics. Companies around the world that couldn’t afford to build their own scale-out, column-oriented analytical databases, or who just didn’t want the hassle, could rent access to a big cloud data warehouse with practically unlimited scalability.
But as transformational as these cloud data warehouses, data lakes, and data lakehouses have been, they still cannot deliver the SQL query performance demanded by some of the biggest companies on the planet.
If your requirement includes analyzing petabytes’ worth of real-time event data combined with historical data, getting the answer back in less than a second, and doing this concurrently thousands of times per second, you find that you quickly exceed the technical capability of the traditional data warehouse.
And that’s where you find yourself entering the realm of a new class of database. The folks at Imply, the company behind the Apache Druid project, call it a real-time analytics database, but other outfits have different names for it.
David Wang, vice president of product marketing at Imply, says Druid sits at the intersection of analytics and applications.![]()
“Analytics always represented large-scale aggregations and group-bys and big filtered queries, but applications always represented a workload that means high concurrency on operational data. It has to be really, really fast and interactive,” he says. “There is this intersection point on the Venn diagram that, when you’re trying to do real analytics, but do it at the speed, the concurrency, and the operational nature of events, then you’ve got to have something that’s purpose built for that intersection. And I think that’s where this category has emerged.”
Druid’s Deepest, Darkest Secrets
Apache Druid was originally created in 2011 by four engineers at Metamarkets, a developer of programmatic advertising solutions, to power complex SQL analytics atop large amounts of high dimensional and high cardinality data. One of the Druid co-authors, Fangjin Yang, went on to co-found and serve as CEO Imply, and he is also a Datanami Person to Watch for 2023.
There’s no single secret ingredient in Druid that makes it so fast, Wang says. Rather, it’s a combination of capabilities developed over years that allow it to do things that traditional databases just can’t do.
“It’s about CPU efficiency,” Wang says. “What we do under the covers is we have a highly optimized storage format that leverages this really unique approach to how we do segmentation and partitioning, as well as how we actually store the data. It’s not just columnar storage, but we leverage dictionary encoding, bit-mapped indexing, and other algorithms that allow us to really minimize the amount of rows and amount of columns that actually have to be analyzed. That makes a huge impact in terms of performance.”
The separation of compute and storage has become standard operating procedure in the cloud, as it enables companies to scale them independently, which saves money. The tradeoff in loss of performance by separating compute and storage and placing data in object stores is acceptable in many use cases. But if you’re reaching for the upper reaches of analytics performance on big, fast-moving data, that tradeoff is no longer feasible.
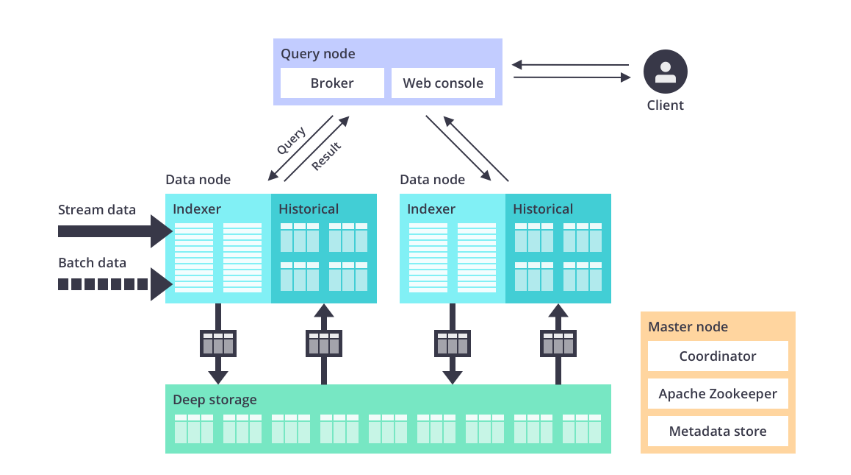
Apache Druid’s architecture (Image source: Apache Druid)
“You can’t get the kind of [high] performance if you don’t have data structured in a certain way that drives the efficiency of the processing,” Wang says. “We definitely believe that, for the really fast queries, where you’re really trying to drive interactivity, you’ve got to do basic things, like don’t move data. If you’re going to have to move data from object storage into you’re the compute nodes at query time you’re getting a hit on network latency. That’s just physics.”
Druid in Action
The SQL analytic offerings from Snowflake, Redshift, and Databricks excel at serving traditional BI reports and dashboards, Wang says. Druid is serving a different class of user with a different workload.
For example, Salesforce’s engineering team is using Druid to power its edge intelligence system, Wang says. Product managers, site reliability engineers (SREs), and various development teams are using Druid to analyze different aspects of the Salesforce cloud, including performance, bugs, and triaging issues, he says.
“It’s all ad-hoc. They’re not predefining the queries in advance of what they’re looking for. It’s not pre-cached. It’s all on-the-fly pivot tables that are being created off of trillions of rows of data and they’re getting instant responses,” Wang says. “Why is Salesforce doing that? It’s because the scale of their event data is at a size that they need a really fast engine to be able to process it quickly.”
Even if a traditional data warehouse could ingest the real time data quickly enough, it couldn’t power the number concurrent queries to support this type of use case, Wang says.
“We’re not trying to fight Snowflake or Databricks or any of these guys, because our workload is just different,” he says. “Snowflake’s maximum concurrency is eight. Your biggest scale-up virtual data warehouse can support eight concurrent queries. You can cluster like eight or 10, so you get 80 QPS [queries per second]. We have customers that run POCs that have thousands of QPS. It’s a different ball game.”

(vecktor/Shutterstock)
‘Spinning Wheel of Death’
Confluent has a similar requirement to monitor its cloud operations. The company that employs the foremost experts in the Apache Kafka message bus selected Druid to power an infrastructure observability offering that’s used both internally (by Confluent engineers) as well as externally (exposed to Confluent customers).
According to Wang, their data requirements were massive. Confluent demanded an analytics database that could ingest 5 million events per second and deliver subsecond query response time across 350 channels simultaneously (350 QPS). Instead of using their own product (ksqlDB) or a streaming data system (Confluent recently acquired an Apache Flink specialist and is developing a Flink offering), they chose Druid.
Confluent, which wrote about its use of Druid, selected Druid due to its ability to query both real-time and historical data, Wang says.
“There is a fundamental difference between a stream processor and an analytic database,” he says. “If you’re trying to just do a predefined query on a continuous stream, then a stream process is going to be quite sufficient there. But if you’re trying to do real time analytics, looking at real-time events comparatively with historical data, then you need to have a persistent data store that supports both real time data as well as historical data. That’s why you need an analytics database.”
Momentum is building for Druid, Wang says. More than 1,400 companies have put Druid into action, he says, including companies like Netflix, Target, Cisco’s ThousandEyes, and major banks. Petabyte-scale deployments involving thousands of nodes are not uncommon. Imply itself has been pushing development of its cloud-based Druid service, dubbed Polaris, and more new features are expected to be announced next month.
As awareness of real-time analytics databases builds, companies find Druid is a good fit for both new data analytics projects, as well as existing projects that needed a little more analytics muscle. Those roads eventually lead to Druid and Imply, Wang says.
“When we’re talking to developers about the analytic projects, we asked them, hey, are there any use cases where performance and scale matter? Where they tried to build an analytic application using…a different database and they hit that scale limitation, where they hit the spinning wheel of death because that architecture wasn’t designed for these type of aggregations at the volume and the concurrency requirements?” he says. “And then we open up a conversation.”
Related Items:
Imply Raises $100M Series D to Make Developers the Heroes of Analytics
Apache Druid Shapeshifts with New Query Engine
Yahoo Casts Real-Time OLAP Queries with Druid
The post Apache Druid Charms in Upper Echelons of OLAP Database Performance appeared first on Datanami.











0 Commentaires