Aerospike this week rolled out new graph database offering that leverages open source components, including the TinkerPop graph engine and the Gremlin graph query language. The NoSQL company foresees the new property graph being used by customers initially for OLTP workloads, such as fraud detection and identity authentication, with the possibility of OLAP functionality in the future.
Aerospike initially emerged as a distributed key-value store designed to store and query data at high speeds with low latencies. Over time, it became a multi-modal database by supporting SQL queries, via the Presto support it unveiled in 2021, as well as the capability to store and query JSON documents, added last year.
When Aerospike executives heard that some of its financial services customers were spending their own time and money developing bespoke graph databases to handle specific compute-intensive tasks–such as detecting fraud in financial transactions–they decided it was a good time to add graph to the mix.
“We had this payment company that had done this at scale,” says Lenley Hensarling, Aerospike’s chief product officer. “And we looked around at other of our customers who are throwing bespoke graph code, hand-coding graphs in order to get the throughput and the scale of data for a real production application of graphs.”
The product developers at Aerospike realized they could take Apache TinkerPop, an open source graph query engine that also forms the heart of the AWS Neptune and the Microsoft Azure Cosmos DB graph database offerings, and integrate it into the Aerospike storage engine. JanusGraph’s Gremlin was selected as the initial graph language, although the company is aiming to support openCypher, which is the open source version of Neo’s graph query language.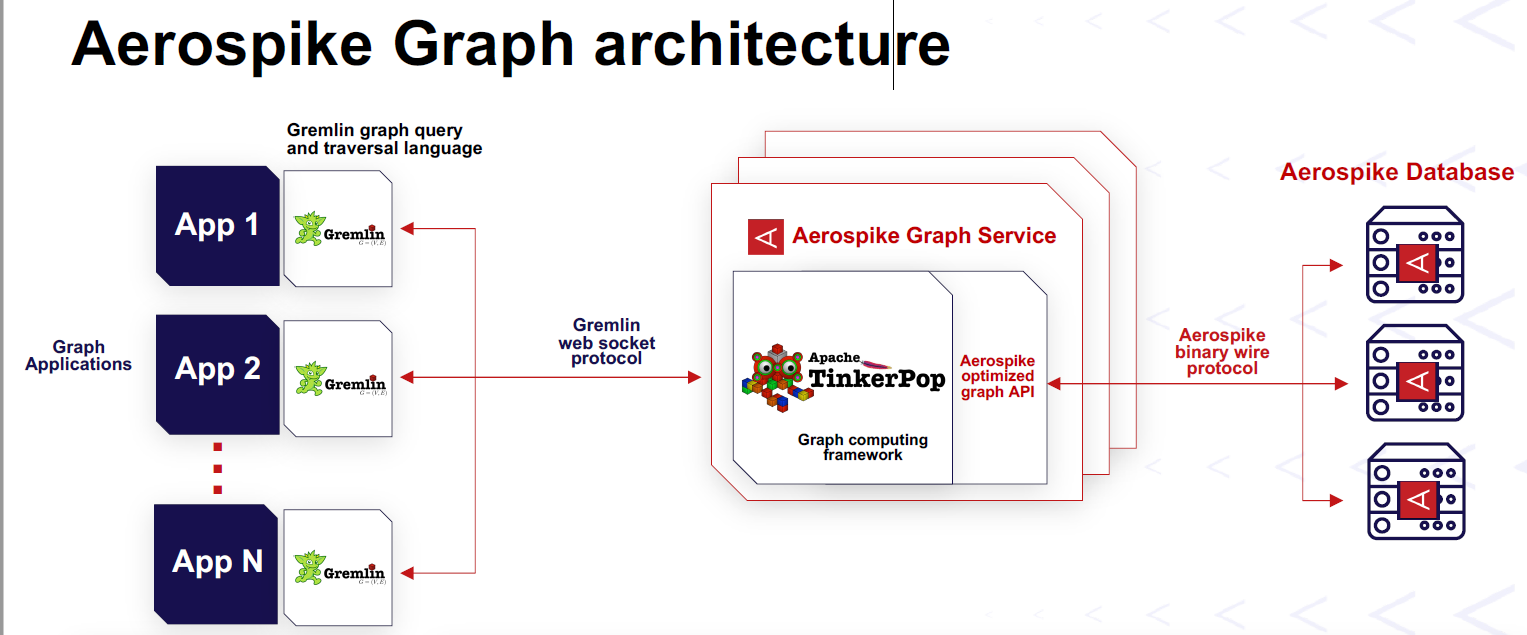
The combination of TinkerPop query engine, Gremlin query language, and Aerospike’s data management capabilities is a general-purpose property graph database that’s suitable for the types of transactional and operational use cases its customers require, Hensarling says.
“There’s just white space for graph solutions at scale,” he tells Datanami. “We believe there’s an unmet need. We can provide tens of thousands to hundreds of thousands to millions of transactions per second. It’s not going to be as fast as the key-value lookup, for sure. But it’s going to be over and over again, for many different applications.”
Fraud detection and identity authentication are the two main use cases that Aerospike sees customers using the graph database to build. Fraud detection, where connections to known fraudulent entities (people, businesses, devices, etc.) can be quickly discovered in real time, is a classic property graph workload.
But modern identity authentication methods today–in which multiple pieces of data are brought to bear to determine that yes, this person is really who they claim to be–are beginning to closely resemble that fraud detection workload, too.
Aerospike has optimized its database to deliver two to five “hops,” which is the number of traversals a query makes as it travels along vertices to find other connected nodes, within a short amount of time. Completing the graph lookup within about 20 milliseconds is the goal, Hensarling says.![]()
“It’s part of a longer transaction,” he says of the graph lookups. “They may use graph for part of it. They may use AI and ML stuff in another part. But they have seconds to do the whole chain of things and typically it’s like 20 milliseconds” for the graph component.
Aerospike worked with Marko Rodriguez, the creator of TinkerPop, to develop a connection to the Aerospike database, Hensarling says. That layer, which Aerospike developers called Firefly, enables OLTP workloads, but a similar layer could be adapted that leverages TinkerPop for OLAP and graph analytics workloads, he says.
The company has done a lot of development work in the past 18 months that prepared it for the move into the graph database realm, Hensarling says. That includes work on secondary indexes, as well as the support for predicate pushdowns, where data processing work is pushed into the database engine. “That has allowed us to do this at a much faster, scalable route than we could have previously,” he says.
For small deployments, all of the storage and query engines could sit in the same namespace, Hensarling says. But large Aerospike graph deployments will likely resemble large Aerospike Trino (or Presto) deployments, where the data is persisted on an Aerospike cluster while the TinkerPop query engine sits on a separate cluster. The TinkerPop cluster will run the queries against the Aerospike data, and will scale horizontally if necessary to handle bigger workloads.
“If you need more throughput, you can just stand up more nodes of TinkerPop,” Hensarling says. “And you can also take them down as you have bursts of transactions, because the data is held in Aerospike and it’s persisted, so you just connect it again and scale out. That’s something people have really responded to as well.”
The graph database has been in beta with Aerospike customers for several months. The largest deployment so far involved a financial transaction processing company that had a graph with billions of vertices and thousands of edges, with responses coming back in 15 milliseconds, Hensarling says.
Aerospike is confident that its new graph offering will resonate with customers, particularly among those that need to combine graph capabilities with other database capabilities.
“There’s an unmet need in the marketplace,” Hensarling says. “People don’t want yet another database all the time. If they can use the skills for operations and leverage them across more types of workloads, that’s good, as long as the performance and the semantic coverage is there.”
Related Items:
Aerospike Adds JSON Support, Preps for Fast, Multi-Modal Future
Aerospike’s Presto Connector Goes Live
Aerospike Turbocharges Spark ML Training with Pushdown Processing
The post Aerospike Is Now a Graph Database, Too appeared first on Datanami.













0 Commentaires