Who do you trust with big data? If you’re Cloudera CEO Rob Bearden, you point out that your company is helping to manage 25 million terabytes of customer data. You also launch a large language model and observability solution, which the company did today.
Cloudera, which once stood proudly atop the Hadoop ecosystem, continues its metamorphosis into a hybrid data management vendor utilizing today’s popular lakehouse, data mesh, and data fabric architectures with built-in support for the latest open frameworks for analytics, AI, and stream processing.
While legacy Cloudera customers can choose to core Hadoop components such as HDFS, MapReduce, Hive, and HBase–and there are plenty of enterprises who spent millions building with them and will rely on them for some time still–the company has moved on and is encouraging new Cloudera Data Platform (CDP) users to deploy the platform in the modern hybrid fashion, utilizing cloud object storage systems separated from compute, with Cloudera’s SDX software handling security and governance across complex data topologies.
Cloudera’s history puts it in a unique position. On the one hand, it is trying to keep up with the rapid pace of technological evolution, as all big data software and services companies are today. Whether it’s lakehouses or data meshes or the impact of large language models (LLMs), the dynamic is such that nobody can rest on their laurels.
Cloudera enables customers to build Applied ML Prototypes (AMPs) using LLMs with Cloudera Machine Learning (image source: Cloudera)
On the other hand, as the last pureplay Hadoop distributor left standing (not counting hyperscalers), the company has a sizable legacy installed base to keep happy. From 2012 to 2019, thousands of companies adopted Hadoop as the de-facto standard for managing big data.
While Hadoop is an effectively a bad word these days and many organizations are turning off their Hadoop clusters, there is still a sizable installed base of Hadoop out there, much of it with Cloudera. Just as IBM mainframes were declared dead starting in the 1970s, the longtail of Hadoop will likely be with us for some time.
This is nothing to sneeze at (although many of its competitors will try). Cloudera boasts large installed bases in all of the top industries, including having eight of the top 10 global banks as customers, all of the top 10 global telcos, the top 10 global auto manufacturers, nine of the top 10 global pharma companies, eight of the top 10 global technology companies, and more than 40 of the largest public sector organizations around the world.
According to Cloudera, its software and services are managing 25 million terabytes on behalf of customers. That is equal to 25,000 petabytes of data, or 25 exabytes. In other words, an enormous amount. Having so much data managed under the Cloudera banner certainly gives Bearden a reason to toot the company’s horn, even if some of it is still residing under HDFS.
“Managing 25 million terabytes of data for customers is on par with the hyperscalers,” said Dan Newman, principal analyst at Futurum Research, which is hosting the Six Five Summit this week. “This places Cloudera in a unique position to help companies unlock value from their data, no matter where it resides. At the same time, the data is AI ready for enterprises to benefit from current and future developments in AI.”
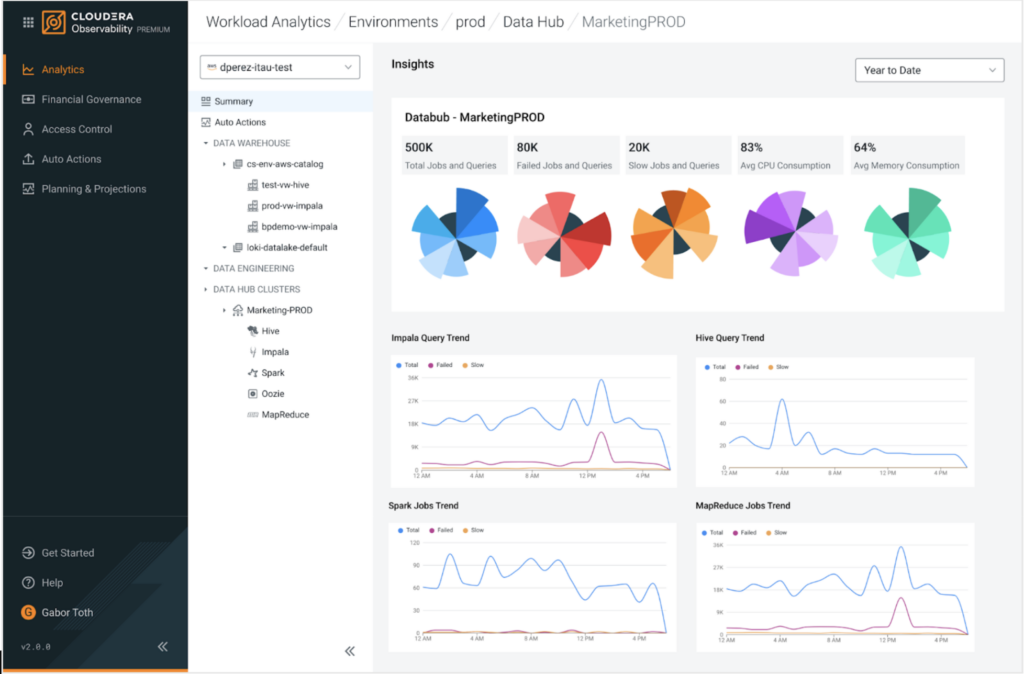
Cloudera Observability provides insights into data, application, and infrastructure usage in CDP clusters on-prem and in the cloud (image source: Cloudera)
According to Bearden, having all that data under management puts Cloudera in a prime position to help its customers utilize the latest in LLM development. To that end, the company today announced a new offering called LLM Chatbot Augmented with Enterprise Data, which is designed to serve as a blueprint for leveraging LLMs and generative AI.
The new offering, which is a component of Cloudera Machine Learning, enables users to build customized chatbot solutions that leverage their own enterprise data and doesn’t require sharing their data with external services, Cloudera says. Customers get to use an open source LLM of their choice, and host it internally, either on the cloud or on-prem.
The Palo Alto, California company also today launched Cloudera Observability, a new solution designed to give its lakehouse customers greater insight into what’s going on with their data, applications, and infrastructure, with an eye on optimizing costs, resolving issues, and improving performance.
“One of the biggest challenges for companies today when managing workloads operating in the cloud is to get a global view of spending on infrastructure and services,” Bearden said in a press release. “With Cloudera Observability customers get unprecedented visibility into workload and resource utilization to better control and automatically manage budget overruns, and improve performance.”
Cloudera has two versions of its observability solution. The first is available to customers at no additional cost as part of applicable subscriptions to CDP and is designed to work with Hive, Impala and Spark for data engineering workloads. The second, dubbed Cloudera Observability Premium, is available at an additional cost and adds capabilities designed to give customers deeper insights, richer automated troubleshooting, and automated actions. The company plans to add support for additional data engines over time.
Reining in excessive spending in the cloud is top-of-mind for many CFOs, and Cloudera’s observability solution is poised to be a handy tool for the CFO. For instance, Cloudera shares the story of how the new observability solution was able to help identify a “rogue user” who initiated millions of unnecessary queries, severely impacting critical workloads. The observability tool helped administrators identify the rogue user and put a stop of the resource drain that he or she initiated.
Cloudera Observability is compatible with Apache Iceberg, the open table format it selected last year. For more information on the new offering, click here.
Cloudera, which became a private company owned by Clayton, Dubilier & Rice in October 2021, made the two announcements today at Futurum Research’s Six Five Summit.
Related Items:
The Key Tech Enabling Cloudera’s New Lakehouse
Cloudera Picks Iceberg, Touts 10x Boost in Impala
Cloudera Begins New Cloud Era with CDP Launch
The post Cloudera: Over 25 Million Terabytes Served appeared first on Datanami.












0 Commentaires