Anaconda made some news yesterday when it announced support for Pandata, a new open-source stack. But just what is Pandata, and should it be on your big data radar?
According to the Pandata GitHub page, Pandata is a collection of scalable Python-based data tools used for scientific, engineering, and analysis workloads. There are more than 20 different Python-based tools listed as being part of Pandata, including familiar names like Pandas, Numba, Dask, Jupyter, Plotly, and Conda.
The Python libraries that make up Pandata were developed separately to provide capabilities for data storage, access, processing, and visualization capabilites among others. But they were designed to work well together, according to GitHub page, which is maintained by James Bednar, the director of custom services at Anaconda.
Pandata is intended to leverage the broad Python ecosystem to deliver the high-performance and scalable data analyses capabilites that the scientific and engineering communities need but are not finding with legacy tool stacks, according to Bednar.
Bednar and fellow Anaconda employee Martin Durant wrote a paper about Pandata for the recent SCIPY 2023 conference. Titled “The Pandata Scalable Open-Source Analysis Stack,” the eight-page paper describes the need for Pandata, and the characteristics of Pandata tools. According to the paper, Pandata is needed to replace older, domain-specific tooling with a new data stack that’s composed of tools that are domain independent, high performance, and scalable.
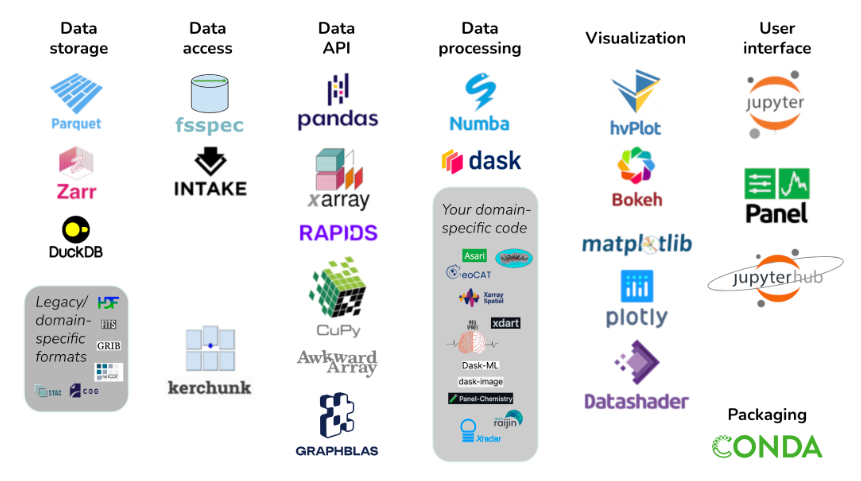
Members of the Pandata ecosystem
“As the scale of scientific data analysis grows, traditional domain-specific software tools are hitting limits when managing increased data size and complexity,” Bednar and Durant write in the paper. “These tools also face sustainability challenges due to a relatively narrow user base, a limited pool of contributors, and constrained funding sources. We introduce the Pandata open-source software stack as a solution, emphasizing the use of domain-independent tools at critical stages of the data life cycle, without compromising the depth of domain-specific analyses.”
The tools in the Pandata stack, which is distributed under a BSD-3-Clause license, all use vectorized computing or JIT compilation and can run on any computer, from the smallest single-core laptop to the largest thousand-node clusters, Bednar and Durant write. The tools are cloud friendly and also run on multiple operating systems and processor types, they write.
There are other characteristics uniting the tools in the Pandata stack, they write. They’re compositional, which means they can be combined together to solve your problem. They’re visualizable, which means they support rendering even the largest datasets without conversion or approximation. They’re interactive, which means they support fully interactive exploration, not just rendering static images or text files. They’re shareable, which means they’re deployable as Web apps for use by anyone anywhere. And lastly, their open source, which means they can be used for research or commercial use, without restrictive licensing.
Anaconda, which has been a force for standardization of Python-based tools in the past, says there are many examples of Pandata being used already. Among the organizations using Pandata are Pangeo, a provider of Python-based tools for geographic data, as well as Project Pythia, which is Pangeo’s education working group.
While the tools in the Pandata stack are extensible and compatible with each other, that doesn’t mean they play nicely with tools in other stacks, even if they were built in Python or leverage other tools in the Python ecosystems.
For instance, the Ray represents an alternative to distributed computation that is not supported by the Pandata tools. “And so if a project uses Ray to manage distributed computation, then they cannot (currently) easily select hvPlot for visualization without first converting the data structures into something hvPlot understands,” Bednar and Durant write.
Similarly, things like Vaex and Polars provide alternatives to the Pandas/Dask dataframes supported in Pandas, they write, while tools like VegaFusion provide a way to render large data sets, but which are not compatible with Pandata. There are other integrated stacks of tools, such as Hadoop and Spark in the Apache ecosystem. However, those tools typicaly require Java, but the heaviness of the JVM makes it difficult to combine those Java tools with lighter weight Python-based tools, they write.
“The Pandata stack is ready to use today, as an extensive basis for scientific computing in any research area and across many different communities,” Bednar and Durant conclude in the paper. “There are alternatives for each of the components of the Pandata stack, but the advantage of having this very wide array of functionality that works well together is that researchers in any particular domain can just get on with their actual work in that domain, freed from having to reimplement basic data handling in all its forms and freed from the limitations of legacy domain-specific stacks. Everything involved is open source, so feel free to use any of these tools in any combination to solve any problems that you have!”
Related Items:
Anaconda Bolsters Data Literacy with Moves Into Education
Anaconda Unveils New Coding Notebooks and Training Portal
Anaconda Unveils PyScript, the ‘Minecraft for Software Development’
The post Inside Pandata, the New Open-Source Analytics Stack Backed by Anaconda appeared first on Datanami.












0 Commentaires