The intersection of large language models and graph databases is one that’s rich with possibilities. The folks at property graph database maker Neo4j today took a first step in realizing those possibilities for its customers by announcing the capability to store vector embeddings, enabling it to function as long-term memory for an LLM such as OpenAI’s GPT.
While graph databases and large language models (LLMs) live at separate ends of the data spectrum, they bear some similarity to each other in terms of how humans interact with them and use them as knowledge bases.
A property graph database, such as Neo4j’s, is an extreme example of a structured data store. The node-and-edge graph structure excels at helping users to explore knowledge about entities (defined as nodes) and their relationships (defined as edges) to other entities. At runtime, a property graph can find answers to questions by quickly traversing pre-defined connections to other nodes, which is more efficient than, say, running a SQL join in a relational database.
An LLM, on the other hand, is an extreme example of unstructured data store. At the core of an LLM is a neural network that’s been trained primarily on a massive amount of human-generated text. At runtime, an LLM answers questions by generating sentences one word at a time in a way that best matches the words it encountered during training.
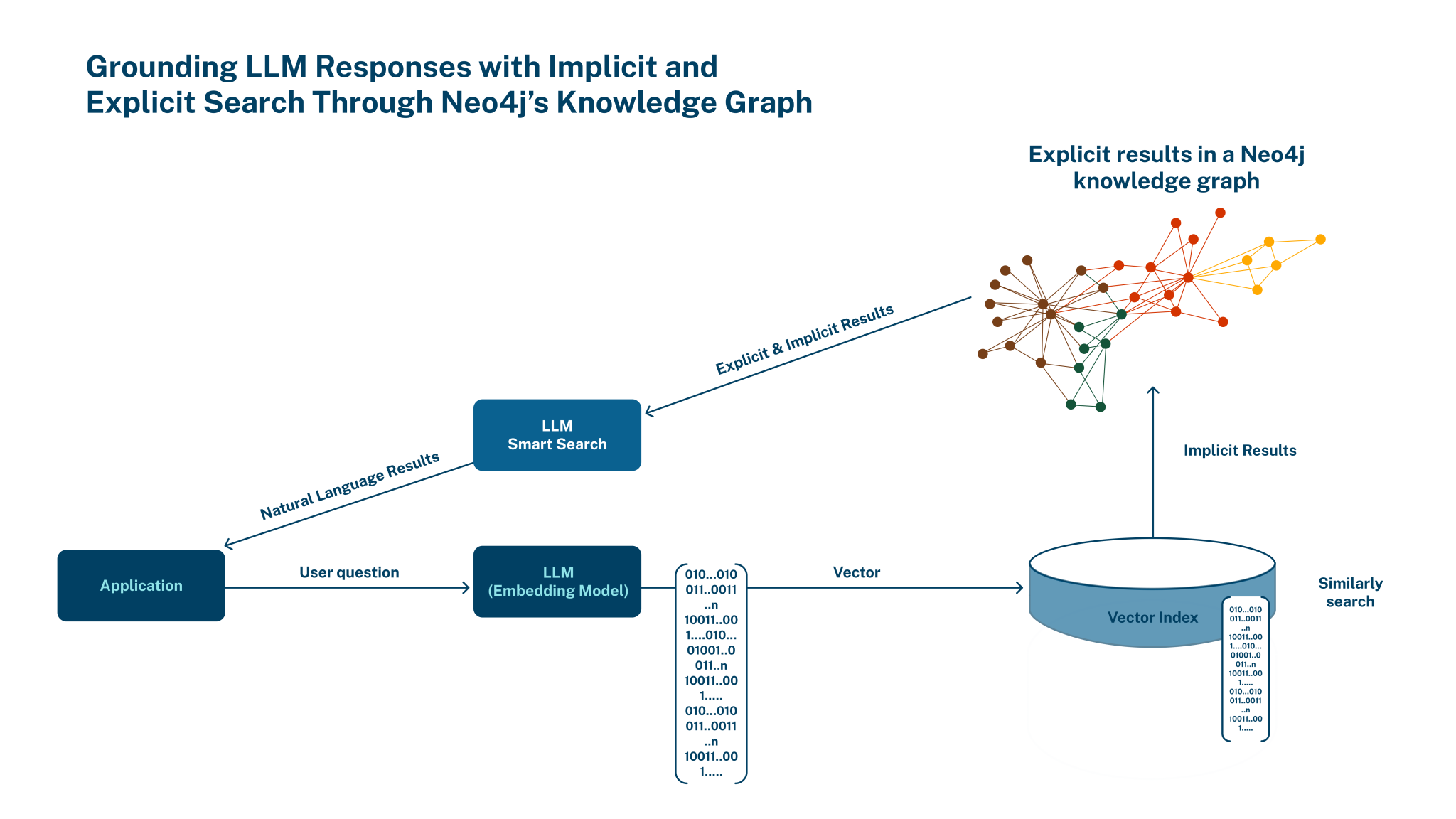
Image source: Neo4j
Whereas the knowledge in the graph database is contained in the connections between labeled nodes, the knowledge in the LLM is contained in the human-generated text. So while graphs and LLMs may be called upon to answer similar knowledge-related questions, they work in entirely different ways.
The folks at Neo recognized the potential benefits from attacking these types of knowledge challenges from both sides of the structured data spectrum. “We see value in combining the implicit relationships uncovered by vectors with the explicit and factual relationships and patterns illuminated by graph,” Emil Eifrem, co-founder and CEO of Neo4j, said in a press release today.
Neo4j Chief Scientist Jim Webber sees three patterns for how customers can integrate graph databases and LLMs.
The first is using the LLM as a handy interface to interact with your graph database. The second is creating a graph database from the LLM. The third is training the LLM directly from the graph database. “At the moment, those three cases seem very prevalent,” Webber says.
How can these integrations work in the real world? For the first type, Webber used an example of the query “Show me a movie from my favorite actor.” Instead of prompting the LLM with a load of text explaining who your favorite actor is, the LLM would generate a query for the graph database, where the answer “Michael Douglas” can be easily deduced from the structure of the graph, thereby streamlining the interaction.
For the second use case, Weber shared some of the work currently being done by BioCypher. The organization is using LLMs to build a model of drug interactions based on large corpuses of data. It’s then using the probabilistic connections in the LLM to build a graph database that can be query in a more deterministic manner.
BioCypher is using LLMs because it “does the natural language hard stuff,” Webber says. “But what they can’t do is then query that large language model for insight or answers, because it’s opaque and it might hallucinate, and they don’t like that. Because in the regulatory environment saying ‘Because this box of randomness told us so’ is not good enough.”
Webber shared an example of the last use case–training a LLM based on curated data in the knowledge graph. Weber says he recently met with the owner of an Indonesian company that is building custom chatbots based on data in the Neo4j knowledge graph.![]()
“You can ask it question about the latest Premiere League football season, and it would have no idea what you’re talking about,” Webber says the owner told him. “But if you ask a question about my products, it answers really precisely, and my customer satisfaction is going through the roof.
In a blog post today, Neo4j Chief Product Officer Sudhir Hasbe says the integration of LLMs and graph will help customers in enhancing fraud detection, providing better and more personalized recommendations, and for discovering new answers. “…[V]ector search provides a simple approach for quickly finding contextually related information and, in turn, helps teams uncover hidden relationships,” he writes. “Grounding LLMs with a Neo4j knowledge graph improves accuracy, context, and explainability by bringing factual responses (explicit) and contextually relevant (implicit) responses to the LLM.”
There’s a “yin and yang” to knowledge graphs and LLMs, Webber says. In some situations, the LLM are the right tool for the job. But in other cases–such as where more transparency and determinism is needed–then moving up the structured data stack a full-blown knowledge graph is going to be a better solution.
“And at the moment those three cases seem very prevalent,” he says. “But if we have another conversation in one year… honestly don’t know where this is going, which is odd for me, because I’ve been around a bit in IT and I usually have a good sense for where things are going, but the future feels very unwritten here with the intersection of knowledge graphs and LLMs.”
Related Items:
The Boundless Business Possibilities of Generative AI
Neo4j Releases the Next Generation of Its Graph Database
The post Neo4j Finds the Vector for Graph-LLM Integration appeared first on Datanami.













0 Commentaires