 Today we are officially announcing that TileDB supports vector search. TileDB is an array database, and its main strength is that it can morph into practically any data modality and application, delivering unprecedented performance and alleviating the data infrastructure in an organization. A vector is simply a 1D array, therefore, TileDB is the most natural database choice for delivering amazing vector search functionality.
Today we are officially announcing that TileDB supports vector search. TileDB is an array database, and its main strength is that it can morph into practically any data modality and application, delivering unprecedented performance and alleviating the data infrastructure in an organization. A vector is simply a 1D array, therefore, TileDB is the most natural database choice for delivering amazing vector search functionality.
We spent many years building a powerful array-based engine, which allowed us to pretty quickly enhance our database with vector search capabilities. Here is why you should care:
- TileDB is more than 8x faster than FAISS (specifically for algorithm IVF_FLAT based on k-means), one of the most popular vector search libraries
- TileDB works on any storage backend, including scalable and inexpensive cloud object stores
- TileDB has a completely serverless, massively distributed compute infrastructure and can handle billions of vectors and tens of thousands of queries per second
- TileDB is a single, unified solution that manages the vector embeddings along with the raw original data (e.g., images, text files, etc), the ML embedding models, and all the other data modalities in your application (tables, genomics, point clouds, etc).
- You can get a lot of value from TileDB as a vector database either from our open-source offering (MIT License), or our enterprise-grade commercial product.
TileDB’s core array technology lies in the open-source (MIT License) library TileDB-Embedded, but we developed the vector-search-specific components in the library TileDB-Vector-Search, which is also open-source under MIT License. Similar to the core library, TileDB-Vector-Search is built in C++, and offers a Python API. In addition, TileDB is developing TileDB Cloud, a commercial product that offers serverless, distributed computing, secure governance, and other appealing features.
Why TileDB for Vector Search?
In vector search, there is a set of N vectors each of length L, one or more query vectors, and a distance function used to compare the vectors. In TileDB, we store the vector dataset in a NxL matrix, i.e., a 2D array. TileDB natively stores arrays and, thus, ingestion, all updates with versioning and time traveling, and reading (aka slicing) are already handled by TileDB Embedded — we literally didn’t need to build any extra code for that.
The additional things we had to build were:
- Indexes for fast (approximate) similarity search
- The fast (approximate) similarity search itself
- APIs that are more familiar to folks using vector databases
We developed all the above in an open-source package called TileDB-Vector-Search, which is built on top of TileDB Embedded. Currently, this package supports:
- A C++ and Python API
- FLAT (brute-force) and IVF_FLAT algorithms (all others are under development)
- Euclidean distance (other metrics are under development)
FLAT is straightforward and rarely used for large datasets, but we included it for completeness. IVF_FLAT is based on K-means clustering and provides very fast, approximate similarity search. The figure below shows the arrays that comprise the “vector search asset”, which is represented in TileDB with a “group” (think of this as a virtual folder). The figure also shows the IVF_FLAT query process at a high level.
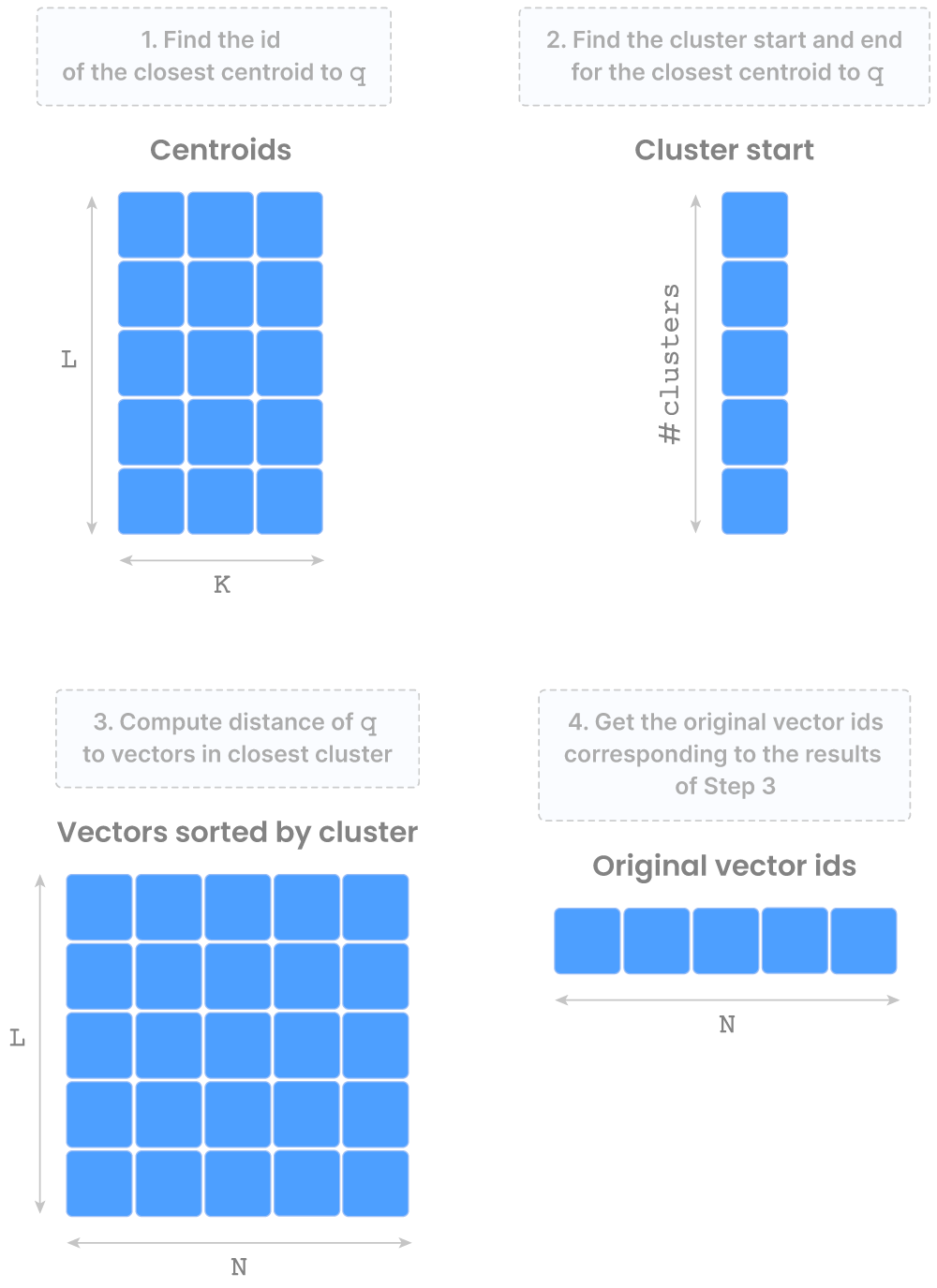
A few cool facts:
- This implementation works in the following modes:
- Single-server, in-memory: Due to the way we store and process arrays in RAM, our IVF_FLAT performance is spectacular; up to 8x faster than FAISS, serving over 60k queries per second based on SIFT 10M, and 2.7k queries per second on SIFT 1B.
- Single-server, out-of-core: TileDB has native, super efficient out-of-core support, so our vector search implementation in this mode inherited the high performance.
- Serverless, cloud store: Due to the fact that we architected TileDB from the ground up to be serverless and work flawlessly on cloud object stores, our vector search implementation delivers superb performance even in this setting, providing unprecedented scalability to billions of vectors while minimizing operational costs.
- TileDB supports batching of queries, i.e., it can dispatch hundreds of thousands of queries together in a bundle. We offer a very optimized implementation of batching, which amortizes some fixed, common costs across all queries, significantly increasing the queries per second (QPS).
- The “serverless, cloud store” mode can leverage the TileDB Cloud distributed, serverless computing infrastructure to parallelize across both queries in a batch, as well as within a single query. This provides unprecedented scalability, QPS and real-time response times even in extreme querying scenarios.
- Regarding the “multi-server, in-memory” mode, we are gathering some more feedback from users. Although it is easy to build (and you can probably build it yourselves leveraging just TileDB’s single-server, in-memory mode), we hypothesize that it is overkill for the users from an operational standpoint, especially in the presence of the more scalable and inexpensive options of “single-server, out-of-core” and “serverless, cloud store”. Please send us a note after you try out those other modes if they do not provide sufficient performance for your use case.
Why TileDB Beyond Vector Search?
We are extremely excited about the vector search domain and the potential of Generative AI. But despite its powerful vector search capabilities, TileDB is more than a vector database.
TileDB is an array database. Arrays are a very flexible data structure that can have any number of dimensions, store any type of data within each of its elements (called cells), and can be dense (when all cells must have a value) or sparse (when the majority of the cells are empty). The sky’s the limit when it comes to what kind of data and applications arrays can capture. You can read all about arrays and their applications in my blog Why Arrays as a Universal Data Model. And if you think that an array database is yet another niche, specialized database, that blog also demonstrates how arrays subsume tables. In other words, arrays are not specialized, but instead they are general, treating tables as a special case of arrays.
TileDB envisions to store, manage and analyze all your data alongside your vector embeddings, including the raw original data you generate your vectors from, as well as any other data your organization might require a powerful database for. Storing multiple data modalities in a single system (1) lowers your licensing costs, (2) simplifies your infrastructure and reduces data engineering, (3) eliminates the data silos enabling a more sane, holistic governance approach over all your data and code assets.
As LLMs are becoming more and more powerful leveraging multiple data modalities, TileDB is the natural choice for internally using LLMs to gain unprecedented insights on your diverse data, leveraging natural language as an API! Imagine extracting instant value from all your data, without thinking about code syntax in different programming languages, understanding the underlying peculiarities of the different data sources, or worrying about security and governance.
Stay tuned for more updates on how we are redefining the “database”!
What’s Next?
You can find more detailed information about TileDB’s vector search capabilities in blog Why TileDB as a Vector Database, and get kickstarted with blog TileDB 101: Vector Search. I also recommend watching our recent webinar Bridging Analytics, LLMs and data products in a single database, which I co-hosted with Sanjeev Mohan.
To learn more about the TileDB-Vector-Search library, check out the github repo and docs. We have a very long backlog on vector search, so look for more articles on our detailed benchmarks, internal engineering mechanics, and LLM integrations.
Feel free to contact us with your feedback and thoughts, follow us on LinkedIn and Twitter, join our Slack community, or read more about TileDB on our website and blog.
The post TileDB Adds Vector Search Capabilities appeared first on Datanami.












0 Commentaires