The jury is still out whether MLOps will survive as a discipline independent of DevOps. There are some who believe MLOps is real, and others who don’t. But what about LLMOps? There are indicators that practitioners need more operational control over large language models, including the inputs fed into them as well as the information they generate.
Professor Luis Ceze became one of the most outspoken critics of MLOps when the idea and the term began trending several years ago. MLOps isn’t needed, the University of Washington computer science professor argued, because the development and maintenance of machine learning models wasn’t so far removed from traditional software development that the technologies and techniques that traditional software developers used–put under the rubric of good ol’ fashioned DevOps–was sufficient for managing the machine learning development lifecycle.
“Why should we treat a machine learning model as if it were a special beast compared to any software module?” Ceze told Datanami in 2022 for the article “Birds Aren’t Real. And Neither Is MLOps.” “We shouldn’t be giving a name that has the same meaning of what people call DevOps.”
Since an LLM is a type of machine learning model, one might surmise that Ceze would be against LLMOps as a distinct discipline, too. But that actually is not the case. In fact, the founder and CEO of OctoML, which recently launched a new LLM-as-a-service offering, said a case can be made that LLMs are sufficiently different from classic machine learning that DevOps doesn’t cover them, and that something else is required to keep LLM applications on the right track.
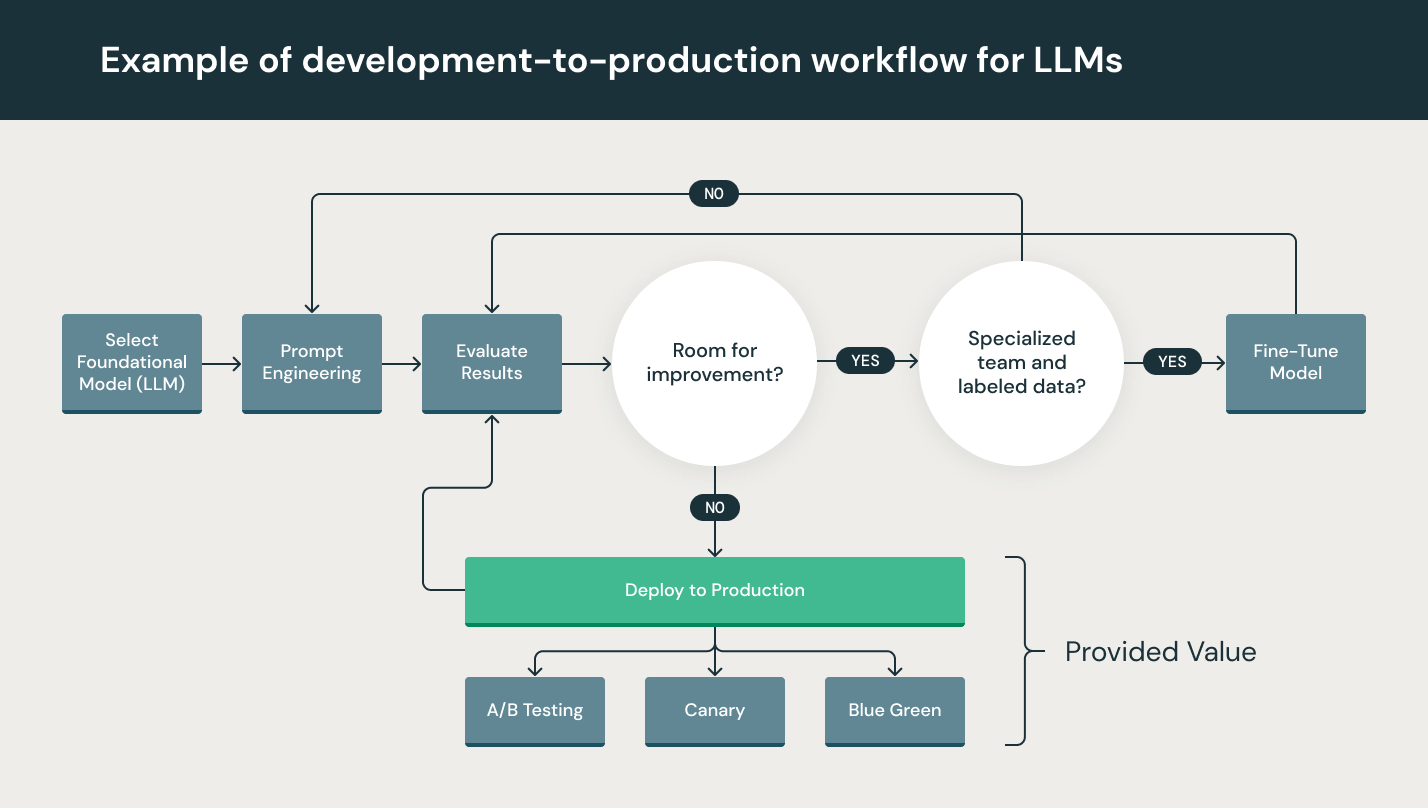
LLMOps for managing the LLM workflow (Image courtesy Databricks)
One of the key drivers of the LLMOps movement is the fact that users often stitch together multiple LLMs to create an AI application. Whether it’s question-answering over a pile of text, generating a custom story, or building a chatbot to answer customer questions, many (if not most) LLM applications will touch multiple foundational models, he said.
“Now that LLMOps is starting to become a thing, [it] touches a number of topics,” Ceze said. “How do you think about prompt management? How do you manage quality? How do you stitch together different LLMs or different foundational models to have an actual feature with the properties that you want? All of this is emerging as a new way of thinking about how you stitch models together to make them behave how you want.”
According to Databricks, the rapid rise of LLMs has necessitated the need to define best practices when it comes to building, deploying, and maintaining these specialized models. Compared to traditional machine learning models, working with LLMs is different because they require much larger compute instances, they’re based on pre-existing models fine-tuned using transfer learning, they lean heavily on reinforcement learning from human feedback (RLHF), and they have different tuning goals and metrics, Databricks says in its LLMOps primer.
Other factors to consider in LLMs and LLMOps include prompt engineering and vector databases. Tools like LangChain have emerged to help automate the process of taking input from customers and converting it into prompts that can be fed into GPT and other LLMs. Vector databases have also proliferated thanks to their capability to store the pre-generated output from LLMs, which can then be fed back into the LLM prompt at runtime to provide a better and more customized experience, whether it’s a search engine, a chatbot, or other LLM use case.
While it’s easy to get started with LLMs and build a quick prototype, the shift into production deployment is another matter, Databricks says.
“The LLM development lifecycle consists of many complex components such as data ingestion, data prep, prompt engineering, model fine-tuning, model deployment, model monitoring, and much more,” the company says in its LLMOps primer. “It also requires collaboration and handoffs across teams, from data engineering to data science to ML engineering. It requires stringent operational rigor to keep all these processes synchronous and working together. LLMOps encompasses the experimentation, iteration, deployment and continuous improvement of the LLM development lifecycle.”

(Oselote/Shutterstock)
Ceze largely agrees. “A lot of a lot of the things we just take for granted in software engineering kind of goes out the window” with LLMs, he said. “When you write a piece of code and you run it, it doesn’t matter if you update say your Python version, or if you compile with a new compiler. You have an expected behavior that that doesn’t change, right?
“But now, looking at a prompt as part of something that you engineer, if it takes the model–even by doing some weight updates…you might actually make that prompt not work as well anymore,” he continued. “So managing all of that I think is really important. We’re just in the infancy of doing that.”
Users often view the foundational models as unchanging, but they may be changing more than most people realize. For instance, a paper recently released by three researchers, including Matei Zaharia, a Databricks co-founder and assistant professor at Stanford University, found a decent amount of variance over time in the performance of GPT-3.5 and GPT-4. The performance of GPT-4 on math problems, in particular, declined 30% from the version OpenAI released in April compared to the one it released in June, the researchers found.
When you factor in all of the other moving parts in building AI applications with LLMs–from the shifting foundational models to the different words people use to prompt a response out of them, and everything in between–it becomes clear that there’s ample room for error to be introduced into the equation.

Luis Ceze is a professor of computer science at the University of Washington and the CEO and co-founder of OctoML
Going forward, it’s not clear how model operations will evolve for LLMs. LLMOps might be a temporary phenomenon that goes away as soon as the developer and community rally around a core set of established APIs and behaviors with foundational models, Ceze said. Maybe it gets lumped into DevOps, like MLOps before it.
“These ensemble of models are going to have more and more reliable behavior. That’s how it’s trending,” Ceze said. “People are getting better at combining output from each of those sources and producing high-reliability output. That’s going to be coupled with people realizing that this is based on functionality that is not always going to be 100%, just like software isn’t today. So we’re going to get good at testing it and building the right safeguards for it.”
The catch is, we’re not there yet. ChatGPT is not even a year old, and the whole GenAI industry is still in its infancy. The business value of GenAI and LLMs is being poked and prodded, and enterprises are searching for ways to put this to use. There’s a feeling that this is the AI technology we’ve all been waiting for, but figuring out how best to harness it needs to be worked out, hence the idea that LLMOPs is real.
“Right now, it feels like a special thing, because an API whose command is an English sentence as opposed to a structured, well-defined call is something that people are building with,” Ceze said. “But it’s brittle. We’re experiencing some of the issues right now and that’s going to have to be sorted out.”
Related Items:
Prompt Engineer: The Next Hot Job in AI
Birds Aren’t Real. And Neither Is MLOps
The post Why LLMOps Is (Probably) Real appeared first on Datanami.













0 Commentaires