
PostgreSQL®, a robust enterprise-grade open source relational database management system, has steadily evolved over three decades, gaining global popularity. This blog delves into PostgreSQL’s architecture, detailing its components and interactions. By grasping these elements, you’ll be empowered to optimize database performance, troubleshoot issues, and make informed design and scaling decisions.
Introduction to PostgreSQL
PostgreSQL is an open source object-relational database management system utilized for both transactional and analytical tasks. Rooted in the SQL programming language, it boasts features for securely storing and effectively scaling complex data workloads. With origins in the 1986 POSTGRES project at UC Berkeley, it boasts over 35 years of continuous development.
Why Choose PostgreSQL?
PostgreSQL’s comprehensive features have propelled it to the forefront of database solutions. Addressing performance, security, programming extensions, and configuration, it supports diverse language-based database functions. Its array of data types spans from primitives to JSONB, hstore, and arrays, and it accommodates custom complex types. The system offers full-text search, robust authentication, access control, and foreign data wrappers for remote data access. Views, materialized views, JSONB document storage, and hstore key-value pairs enable storage and retrieval of semi-structured data alongside relational data.
The Core PostgreSQL Architecture
Operating on the client-server model, PostgreSQL accommodates multiple clients, whether local or remote. Upon client connection, the main process forks new processes for each connection, limited by available CPU cores and RAM. Connection pooling optimizes this by pre-establishing connections to serve clients, improving performance by eliminating connection creation times.
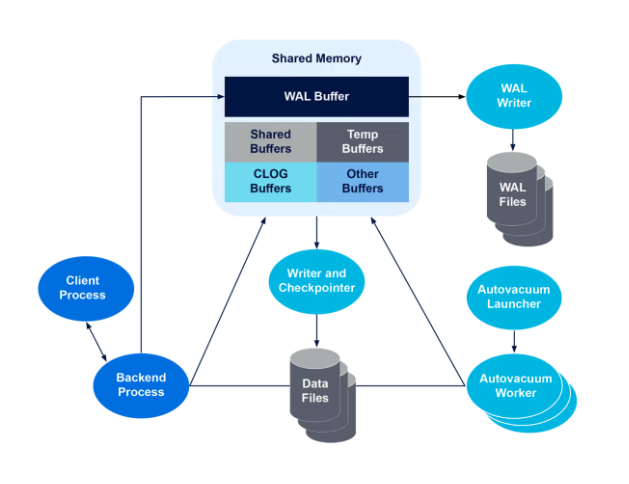
Types of PostgreSQL Processes
PostgreSQL comprises three process categories: Server Processes, Backend Processes, and Background Worker Processes. The PostgreSQL Server Process (formerly Postmaster) manages client connections and backend process initiation. Backend Processes handle query execution and transaction management for clients. Background Worker Processes perform database maintenance and system-wide administration tasks.
Memory Management in PostgreSQL
Memory significantly influences PostgreSQL’s inter-process communication and performance. It’s classified into local memory, used by backend processes for queries, and shared memory for PostgreSQL Server. Shared memory facilitates inter-process communication and holds table data. Shared Buffers and WAL Buffers enhance database efficiency, caching IO operations and managing transaction logs for recovery.
PostgreSQL’s Database Structure
Logically, PostgreSQL employs clusters, databases, schemas, tables, columns, indexes, views, functions, triggers, and sequences. Clusters contain databases managed by a single server, databases consist of schemas, and schemas organize database objects. Tables hold records in rows and attributes in columns. Indexes expedite data retrieval, views offer virtual tables for query encapsulation, and constraints maintain data integrity.
Physically, each database has its directory, with tables stored as files within. PostgreSQL uses heap files for data storage. These contain records of fixed lengths and are appended sequentially. Shared Buffers cache frequently accessed data, improving performance.
Roles, Privileges, and Object Hierarchies
Roles and privileges ensure secure database access. Roles can be assigned to individuals or grouped for efficient permission management. Privileges dictate actions roles can perform within the database. PostgreSQL’s object hierarchy, including clusters, databases, schemas, tables, columns, indexes, views, functions, triggers, and sequences, facilitates organized data management.
Replication, Load Balancing, and High Availability
PostgreSQL supports physical and logical replication, enhancing data availability and read performance. Load balancing distributes queries across nodes, while high availability is ensured by primary-replica architecture and cluster managers like Patroni.
Conclusion
Understanding PostgreSQL’s architecture is vital for maximizing its potential. A deep grasp of its inner workings empowers you to address challenges, optimize performance, and ensure data reliability. While PostgreSQL is low-maintenance, regular tasks like vacuuming, reindexing, and log management are essential. Instaclustr Managed Service for PostgreSQL offers expert management for uninterrupted application building and scaling.
Spin Up a Free PostgreSQL Cluster
The post Understanding the Fundamentals of PostgreSQL® Architecture appeared first on Datanami.













0 Commentaires