Customers that use the high-speed cache in the new Alluxio Enterprise AI platform can squeeze up to four times as much work out of their GPU setups than without it, Alluxio announced today. Alluxio also says the overall model training pipeline, meanwhile, can be sped up to 20x thanks to the data virtualization platform and its new DORA architecture.
Alluxio is better known in the advanced analytics market than in the AI and machine learning (ML) market, which is a result of where it debuted in the data stack. Originally developed as a sister project to Apache Spark by Haoyuan “HY” Li–who was also a co-creator of Spark at UC Berkeley’s AMPlab–Alluxio gained traction by serving as a distrbuted file system in modern hybrid cloud environments. The product’s real forte was providing an abstraction layer to accelerate I/O for data between storage repositories like HDFS, S3, MinIO, and ADLS and processing engines like Spark, Trino, Presto, and Hive.
By providing a single global namespace across hybrid cloud environments built around the precepts of separation of compute and storage, Alluxio reduces complexity, bolsters efficiency, and simplifies data management for enterprise clients with sprawling data estates measuring in the hundreds of petabytes.
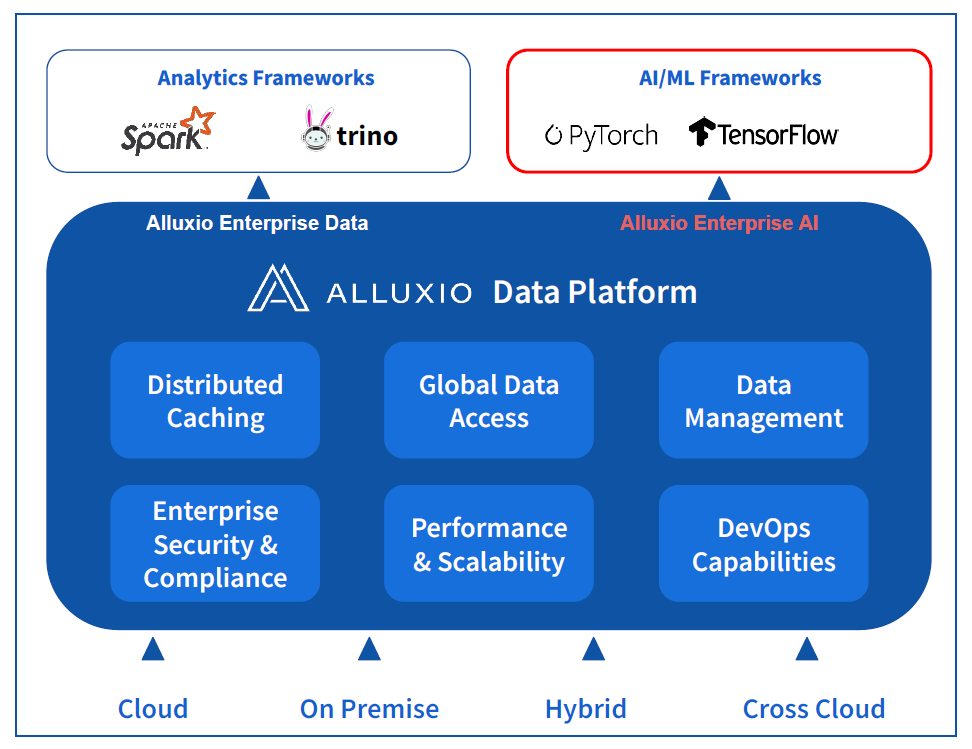
Alluxio now works with analytics and AI workloads
As deep learning matured, the folks at Alluxio realized that an opportunity existed to apply its core IP to help optimize the flow of data and compute for AI workloads too–predominantly computer vision use cases but also some natural language processing (NLP) too.
The company saw that some of its existing analytic customers had adjacent AI teams that were struggling to expand their deep learning environments beyond a single GPU. To cope with the challenge of coordinating data in multi-GPU environments, customers either bought high performance storage appliances to accelerate the flow of data into GPUs from their primary data lakes, or paid data engineers to write scripts for moving data in a more low-level and manual fashion.
Alluxio saw an opportunity to use its technology to do essentially the same thing–accelerate the flow of training data into the GPU–but with more orhcestration and automaton around it. This gave rise to the creation of Alluxio Enterprise AI, which Alluxio unveiled today.
The new product shares some technology with its existing product, which previously was called Alluxio Enterprise and now has been rebranded as Alluxio Enterprise Data, but there are important differences too, says Adit Madan, the director of product management at Alluxio.
“With Alluxio Enterprise AI, even though some of the functionality sounds and is very familiar to what was there in the Alluxio, this is a brand new systems architecture,” Madan tells Datanami. “This is a completely decentralized architecture that we are naming DORA.”
With DORA, which is short for Decentralized Object Repository Architecture, Alluxio is, for the first time, tapping into the underlying hardware, including GPUs and NVMe drives, instead of living purely at the software level.
“We are saying use Alluxio on your accelerated compute itself,” i.e. the GPU nodes, Madan says. “We will make use of NVME, the pool of NvME that you have available, and provide you with the I/O demand by simply pointing to your data lake without the need for another high performance storage solution underneath.”
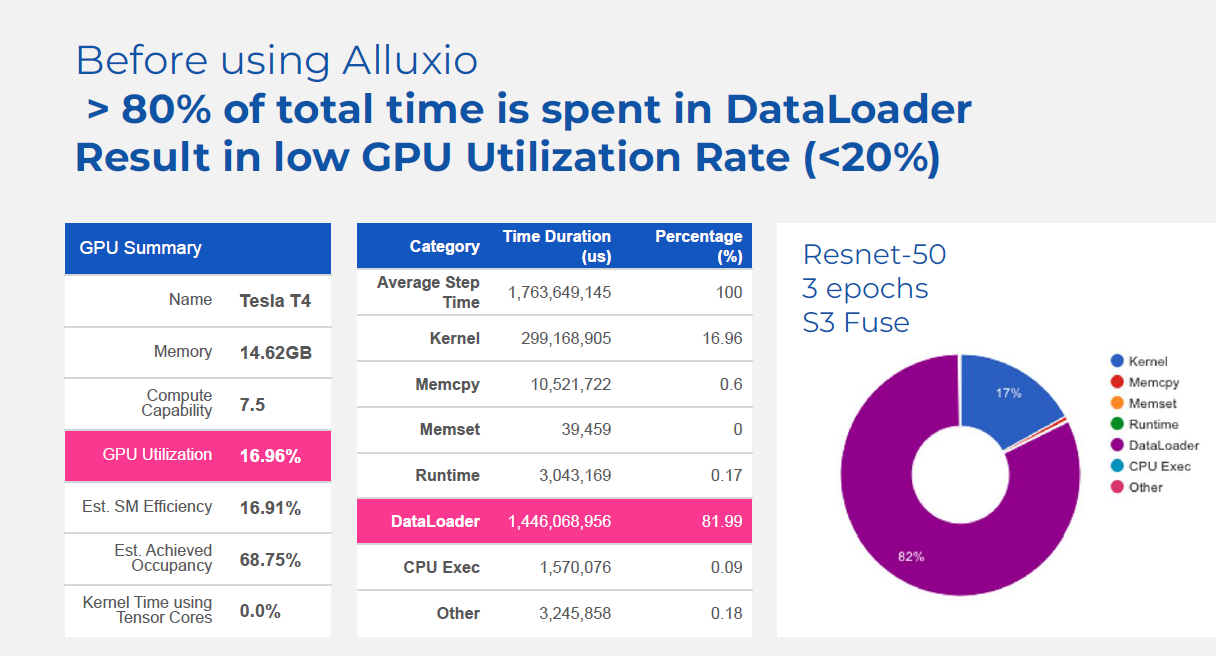
Source: Alluxio
Additionally, Alluxio Enterprise AI leverages techniques that Alluxio has used on the analytics side for some time to “make the I/O more intelligent,” the company says. That includes optimizing the cache for data access patterns commonly found in AI environments, which are characterized by large file sequential access, large file random access, and massive small file access. “Think of it like we are extracting all of the I/O capabilities on the GPU cluster itself, instead of you having to buy more hardware for I/O,” Madan says.
Conceptually, Alluxio Enterprise AI works similarly to the company’s existing data analytics product–it accelerates the I/O and allows users to get more work done without worrying so much about how the data gets from point A (the data lake) to point B (the compute cluster). But at a technology level, there was quite a bit of innovation required, Madan says.
“To co-locate on the GPUs, we had to optimize on how much resources that we use,” he says. “We have to be really resource efficient. Instead of let’s say consuming 10 CPUs, we have to bring it down to only consuming two CPUs on the GPU node to serve the I/O. So from a technical standpoint, there is a very significant difference there.”
Alluxio Enterprise AI can scale to more than 10 billion objects, which will make it useful for the many small files used in computer vision use cases. It’s designed to integrate with PyTorch and Tensorflow frameworks. It’s primarily intended to be used for training AI models, but it can be used for model deployment too.
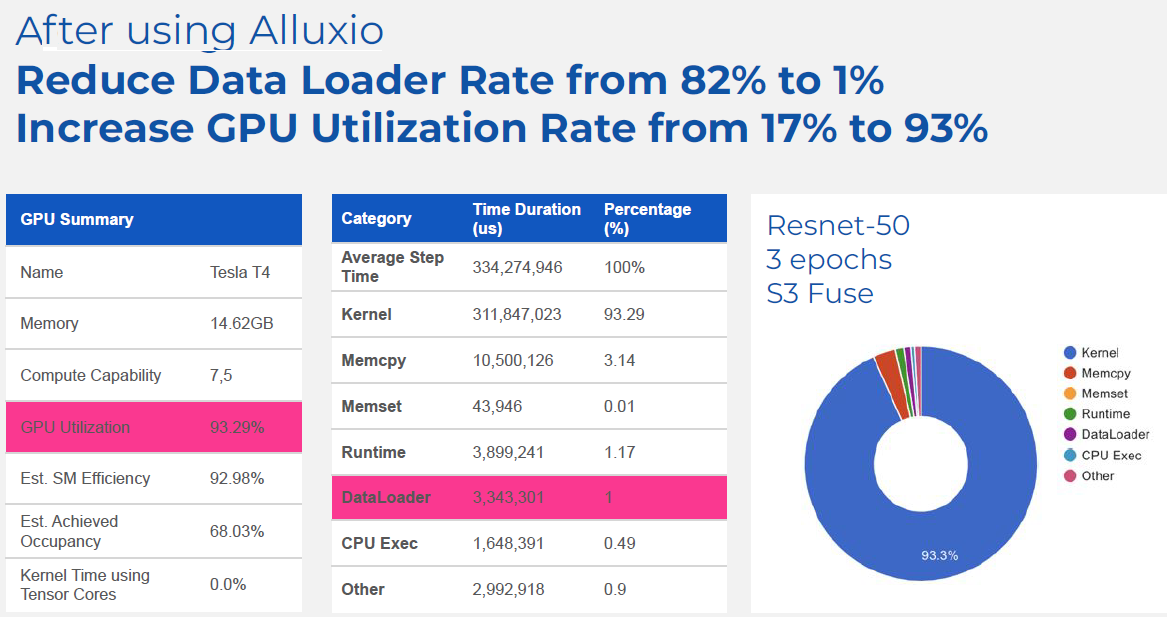
Source: Alluxio
The results that Alluxio claims from the optimization are impressive. On the GPU side, Alluxio Enterprise AI delivers 2x to 4x more capacity, the company says. Customers can use that freed up capacity to either get more computer vision training work done or to cut their GPU costs, Madan says.
Some of Alluxio’s early testers used the new product in production settings that included 200 GPU servers. “It’s not a small investment,” Madan says. “We have some active engagement with smaller [customers running] a few dozen. And we have some engagements which are much larger with a few hundred servers, each of which cost a few hundred grand.”
One early tester is Zhihu, which runs a popular question and answer site from its headquarters in Beijing. “Using Alluxio as the data access layer, we’ve significantly enhanced model training performance by 3x and deployment by 10x with GPU utilization doubled,” Mengyu Hu, a software engineer in Zhihu’s data platform team, said in a press release. “We are excited about Alluxio’s Enterprise AI and its new DORA architecture supporting access to massive small files. This offering gives us confidence in supporting AI applications facing the upcoming artificial intelligence wave.”
This solution is not for everyone, Madam says. Customers that are using off-the-shelf AI models, perhaps with a vector database for LLM use cases, don’t need this. “If you’re adapting your model [i.e. fine-tuning it] that’s where the need is,” he says.
Related Items:
Alluxio Nabs $50M, Preps for Growth in Data Orchestration
Alluxio Claims 5X Query Speedup by Optimization Data for Compute
Alluxio Bolsters Data Orchestration for Hybrid Cloud World
The post Alluxio Touts 4X Greater GPU Utilization for AI Training appeared first on Datanami.













0 Commentaires