Data quality is a critical must-have for big data analytics and AI. If you have it, you can do amazing things with your data. But if you don’t, you’re kind of dead in the water. Behavioral analytics platform provider Amplitude understands the importance of data quality, and recently it has started using generative AI to ensure it stays that way.
Founded in 2014, Amplitude is a Silicon Valley software company that provides a cloud-based platform for analyzing behavioral data at scale. Companies like PayPal, DoorDash, Capital One, and Walmart use Amplitude and its collection of product analytics and A/B testing tools, all delivered atop a customer data platform (CDP), to better understand what their customers are doing so they can improve their experiences.
Ensuring the quality of data has always been challenging in a customer data context, says Jeffrey Wang, Amplitude’s co-founder and chief architect.
“Cleaning up data, making it high quality, is very hard,” Wang tells Datanami. “If there’s anything we’ve learned over the last 10 years, it’s that this is often the biggest blocker to using data well. The quality is just bad. You can’t trust it. You can’t understand it well enough to use it.”
There’s a perception that the best way to solve data quality problems is to just throw the most advanced machine learning algorithm at it. But that only makes the problem worse, Wang says. “If your data is bad, it doesn’t actually matter,” he says.
It’s possible to solve data quality problems, but it often requires a multi-faceted solution and a lot of hard work. For example, if data is being corrupted as it flows into the CDP, then perhaps the data pipes or the instrumentation around it are broken, Wang says.
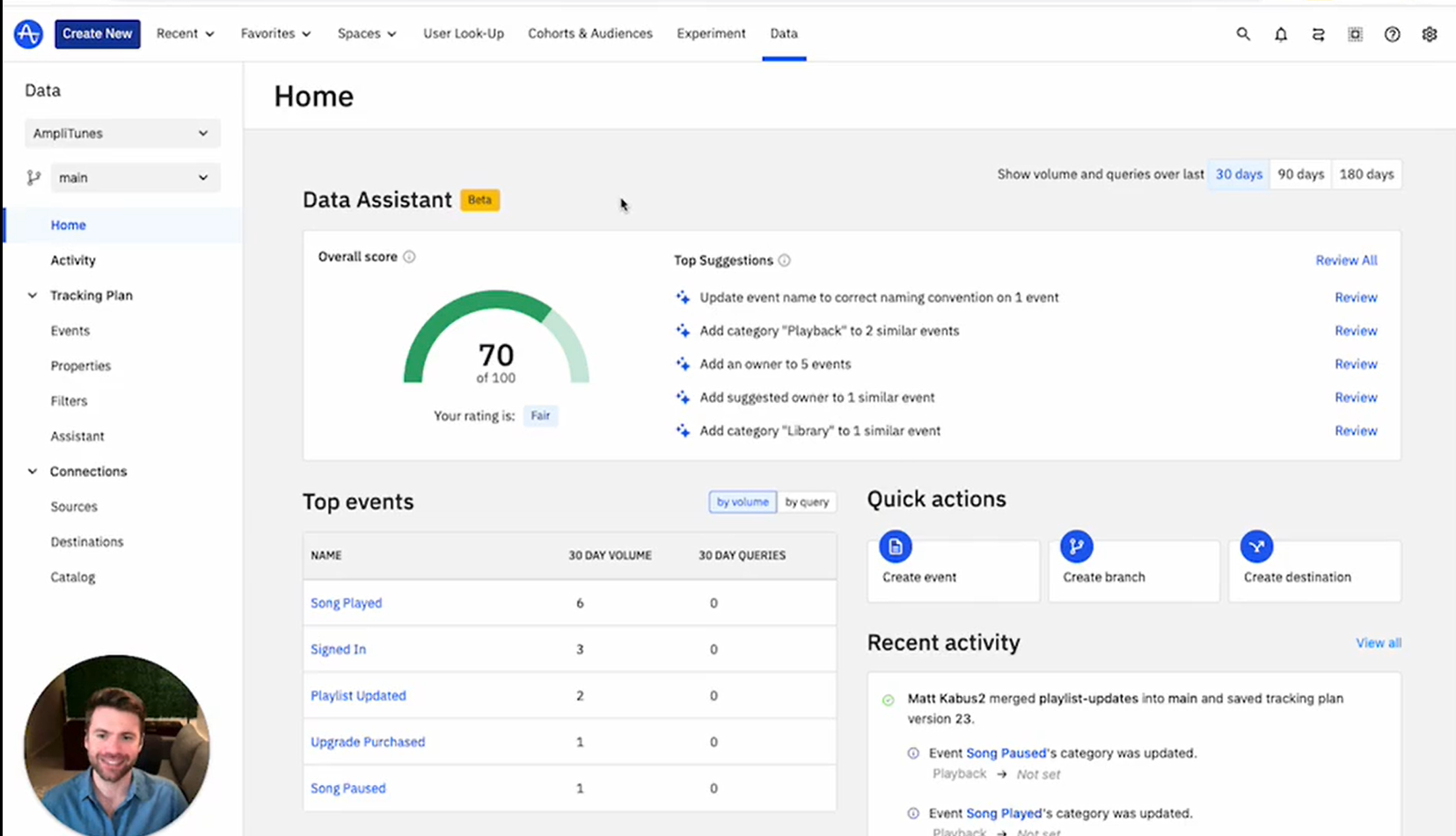
Amplitude’s new Data Assistant uses GenAI to surface insights about customers’ data quality
In the end, there’s no replacement for humans being engaged with the data and actively governing it. In Amplitude, that engagement is delivered via data governance tools that help to accelerate data governance among large groups of users.
“We have a bunch of data governance tools with Amplitude to make that usable, because our goal is to enable non-technical people to get value out of that data,” Wang says. “The less technical the end user, the more important good governance and data quality is.”
In August, Amplitude added another layer to its data quality and data governance strategy. Dubbed the Data Assistant, the tool uses generative AI to help automate data quality and governance tasks. According to Wang, Data Assistant utilizes natural language powers of large language models (LLMs) to provide a better match between how users think and talk about the data with the way it’s actually governed and stored.
“We basically surface a bunch of automated suggestions, like ‘This is how your current data catalog is tracking…in terms of how data is categorized or how it’s described or how it’s showing up to end users. It is not good. It is preventing them from figuring things out.’”
As data flows into Amplitude, it’s given a priority rating and classified as a certain event type within the Amplitude data catalog. Each event type has one or more users who are assigned as the owner. The Data Assistant uses the similarity search capabilites of GenAI to identify common patterns, which helps it to generate an accurate category recommendation. That, in turn, helps improve data quality, which impacts downstream analytics and AI use cases.
“Because GenAI understands natural language, it’s much more suited to solve those types of problems,” Wang says. “And so if you can build out a data catalog where everything has consistent naming that is interpretable and described super well for your end users to consume, then that itself will generate a ton more activity on top of that data.”![]()
Amplitude is using generative AI and LLMs in another way beyond the Data Assistant: generating code to power queries. The company has long sought to democratize data analytics and data science to lower the barrier to doing great things with data, and GenAI fits right into that goal.
“When you give a non-technical user SQL, they have no idea what to do,” Wang says. “When you give them Amplitude, which is kind of a UX for chart building and describing analysis in business terms, they’re pretty good. But there’s a next level, which is now assume that they don’t have to even learn Amplitude.”
With the new Ask Amplitude feature, customers can query the CDP using regular English phrases. For example, if a user from network TV company wanted to know what shows were popular on the Internet, she could ask that in very basic terms, and Ask Amplitude will use OpenAI’s GPT models under the covers to deliver the specific filters and ultimately generate the code needed to complete the query.
“This is very much OpenAI powered, where you take that question and we basically break it down into a bunch of sub-questions, like what type of analysis are you trying to create? What events are you analyzing? What filters would you want to apply to that?” Wang says. “We turn those all into OpenAPI calls that kind of join together all of the data that Amplitude has about what your data looks like, what people analyze, with the natural language processing capabilities of Open AI to construct an analysis.”
Some BI and analytic vendors are adopting similar natural language interfaces for their products, essentially converting natural language to SQL, which appears to have had a smattering of success over the past 10 months. But Wang argues that Amplitude has an advantage over general-purpose SQL-generating BI tools because of the deep context that its environment has for the analytics domain in which it operates, and also because it has its own domain-specific query language.

(Ebru-Omer/Shutterstock)
“Because SQL is so flexible and it doesn’t have any semantics to it, it’s just arbitrary computation. It’s very hard for natural language to go to it,” he says. “With every question I ask, there’s so much inherent ambiguity in what the SQL would even be. And so the fact that Amplitude is more semantic and understands the business domain a lot better, that makes the natural language process a lot more feasible.”
That ambiguity makes SQL just too powerful to put into the hands of regular users in many cases, Wang says. “The scope of potential queries is so big that you actually want to go put some layers on top of it to translate to the natural language first,” he says.
As natural language has become a better user interface over the past year, it’s changing how Wang views graphical user interfaces (GUIs). When Amplitude started, it sought to build the most intuitive GUI that it could, because that was the best way to bridge the gap between the underlying complexity of SQL and SQL-like languages and what the user understands.
“But now that natural language has crossed a very important boundary, it’s possible…that natural language is a better UX to your semantic layer than a normal chart-building capability,” he says.
Related Items:
GenAI and the Future of Work: ‘Magic and Mayhem’
GenAI Debuts Atop Gartner’s 2023 Hype Cycle
GenAI Adoption, By the Numbers
The post How Amplitude Uses GenAI to Improve Data Quality appeared first on Datanami.













0 Commentaires