Getting access to the right data in the right amounts remains a major obstacle for a range of digital endeavors, from developing AI models to testing software applications. If you find yourself short of valuable tabular data, you may consider using Synthetic Data Vault (SDV), an open source project that originated at the Massachusetts Institute of Technology in 2018 and is the basis for an enterprise product at Datacebo.
The SDV project started at MIT around 2016 timeframe, according to SDV co-creator Kalyan Veeramachaneni, who’s a principal research scientist at MIT and the co-founder of Datacebo. Veeramachaneni and his grad students were working on a project to create a synthetic digital student. Neha Patki, one of the grad students, spearheaded the creation of the first SDV algorithm.
“We piloted that on an educational data set,” Veeramachaneni said. “That project turned out to be successful. And then we decided, well, if it’s going to be this successful for this particular case, how pervasive is this problem of data access? And then how generalizable is this solution?”
It turns out that lack of access to data is quite pervasive. And considering the fact that SDV, which is available under a BSL license, reached the 1 million download mark earlier this year, it’s safe to say, in hindsight, that the solution is quite generalizable, too.![]()
The crux of the problem is that, for certain use cases, developers and data scientists simply do not have enough of the right kind of data.
For instance, if you’re training a machine learning model to spot fraudulent transactions, the vast majority of your real world data is going to reflect legitimate transactions. Similarly, if you’re launching a new product on an online e-commerce site, you’re liable to lack real-world user data that contains certain demographic properties.
“If you have 1% fraud and 99% not fraud and you’re trying to build a fraud prediction model [that’s a problem],” he said. “Whether it’s fraud or failure of a turbine, there’s always these cases where the actual occurrence that you want to predict is a very low-frequency event.”
Big data famously has the three Vs–volume, velocity, and variety. But increasing the first V doesn’t necessarily get you more of the third V.
“You don’t actually increase the variety in the data by just collecting more data, because a lot of times you end up collecting more of the same and more of the same, over and over again,” Veeramachaneni told Datanami in a recent interview. “So more data just reinforces the same thing. In many cases, you don’t actually get the variety.”
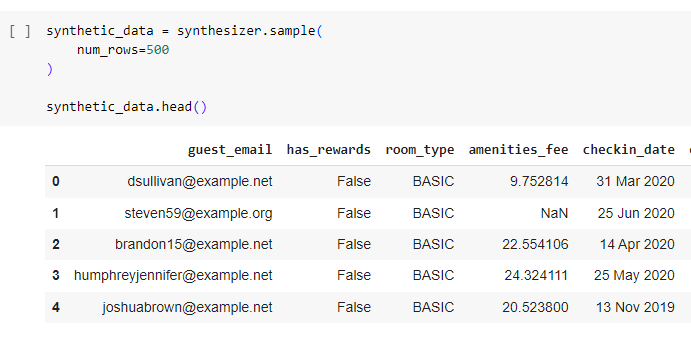
SDV generates tabular data that very closely resembles real data
The good news is that users can create their own variety using tools like SDV. The product isn’t a generative model itself. Instead, it’s a collection of algorithms that allow users to create their own generative model, which they can then use to create their own synthetic data based on existing samples, Veeramachaneni said.
While other synthetic data solutions focus on generating images or text, the SDV ecosystem of tools is unique in that it focuses almost exclusively on tabular data. The open source offering can model data in up to five tables or 10 columns, generating data that exists within constraints set by the user. It supports multi-sequence data, and the synthetic data can be anonymized too.
Veeramachaneni and his team have created several other tools as part of the SDV ecosystem, all of which are distributed under a BSL license. In addition to the core SDV product, there are:
- Copulas, which models and generates tabular data with classic statistical methods and multivariate copulas;
- CTGAN, which models and generates tabular data using a deep learning approach;
- DeepEcho, which models and generates time series data with a mix of classic statistical models and deep learning;
- And RDT, which discovers properties and transforms data for data science use
Spinning Out Datacebo
As downloads of SDV started to pile up in 2019 and 2020, Veeramachaneni decided it was time to spin the work out into a private venture. In November 2020, he convinced his former grad student Patki to leave her tech job at YouTube and join him in co-founding Datacebo. The old MIT team also joined him at the Boston, Massachusetts startup.
At Datacebo, Veeramachaneni and his team have concentrated on tackling a major challenge: creating synthetic versions of enterprise data.
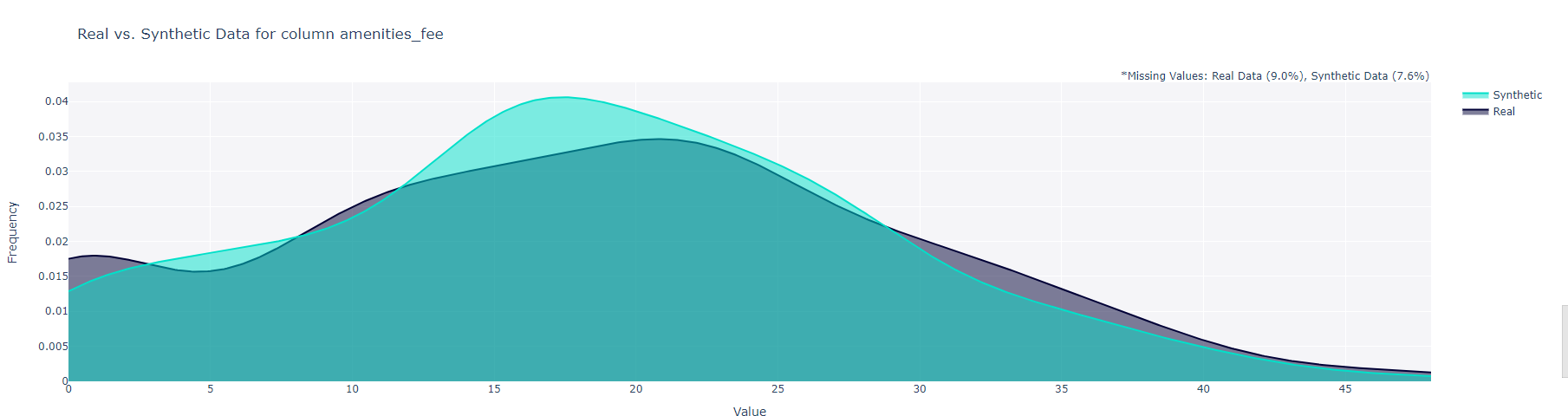
Data generated with SDV matches the mathematical characteristics of real data
“Enterprise complexity–it’s just wild,” he said. “Large enterprises may have like 4,000 applications…So just that whole spectrum is wildly unexplored. The only place where people have created synthetic data is they’ve manually written some rules and create data. Now we have the ability to learn from the database and create synthetic data as realistic as possible.”
In his MIT days, they used to call enterprise data “real world” data to differentiate it from academic data sets. But the availability of so-called “real world” data, such as the famous taxi ride data set, has tarnished the term, Veeramachaneni said.
“They’re so massaged and so clean,” he said. “They are coming from real world, but they are not representative of enterprise.”
Enterprise data is a challenge not just because of the volume, but the overall level of complexity. For instance, to generate a synthetic version of a database table, you have to take into account all the hierarchical relationships that may exist in the database.

Kalyan Veeramachaneni is the co-creator of SDV and the co-founder of Datacebo
“You can’t flatten it out,” Veeramachaneni said. “You have to traverse all that relationships and build models that capture all of your intricacies in the data set.”
Enterprise data is also full of errors and quality problems. The synthetic enterprise data created by Datacebo also has errors and quality problems.
“If you have measurement errors or null values, we synthesize those as well,” Veeramachaneni said. “Otherwise, all the other software that gets tested or uses the downstream applications will get a nice version of the data, but when the real data hits them, they will stop working. So we recreate as much as possible all the idiosyncrasies of the data.”
Not all enterprise data resides in databases, and Datacebo’s flagship product, SDV Enterprise, also support log data, including Web logs, security logs, and JSON logs. The enterprise product can also generate synthetic data from scratch, whereas the open source product requires real data as a guide.
Datacebo is gaining traction in several industries with SDV Enterprise, including financial services and automotive. The company also has clients in the pharmaceutical industry, where they’re using the product to create synthetic data from drug trials, Veeramachaneni said.
The company recently released a metrics library called SDMetrics that allows customers to measure synthetic data for various properties. “That has become a really popular library to measure synthetic data, how close is it to real,” Veeramachaneni said.
It also released SDGym, which allows users to evaluate synthetic data across multiple aspects, including the feasibility of the data, privacy preservation, and downstream application metrics.
OpenAI CEO Sam Altman recently said that in the future, all data will be synthetically created. While Veeramachaneni wasn’t ready to go that far, he does believe that synthetic data will play an increasingly more central role as AI improves.
“It will just improve the access and productivity of people,” he said. “That doesn’t mean that you have to get rid of the real data. You still have that real data, but you just can do a lot of work, get a lot of work done just using synthetic data and make people productive.”
Related Items:
Five Reasons Synthetic Data Is the Electrolyte to Speed Up Your AI Initiatives
Fake Data Comes to the Forefront
Faulty Data is Stalling AI Projects
The post SDV: A Generative Model for Creating Synthetic Data appeared first on Datanami.












0 Commentaires