Monte Carlo has made a name for itself in the field of data observability, where it uses machine learning and other statistical methods to identify quality and reliability issues hiding in big data. With this week’s update, which it made during its IMPACT 2024 event, the company is adopting generative AI to help it take its data observability capabilities to a new level.
When it comes to data observability, or any type of IT observability discipline for that matter, there is no magic bullet (or ML model) that can detect all of the potential ways data can go bad. There is a huge universe of possible ways that things can go sideways, and engineers need to have some idea what they’re looking for in order to build the rules that automate data observability processes.
That’s where the new GenAI Monitor Recommendations that Monte Carlo announced yesterday can make a difference. In a nutshell, the company is using a large language model (LLM) to search through the myriad ways that data is used in a customer’s database, and then recommending some specific monitors, or data quality rules, to keep an eye on them.
Here’s how it works: In the Data Profiler component of the Monte Carlo platform, sample data is fed into the LLM to analyze how the database is used, specifically the relationships between the database columns. The LLM uses this sample, as well as other metadata, to build a contextual understanding of actual database usage.
While classical ML models do well with detecting anomalies in data, such as table freshness and volume issues, LLMs excel at detecting patterns in the data that are difficult if not impossible to discover using traditional ML, says Lior Gavish, Monte Carlo co-founder and CTO.
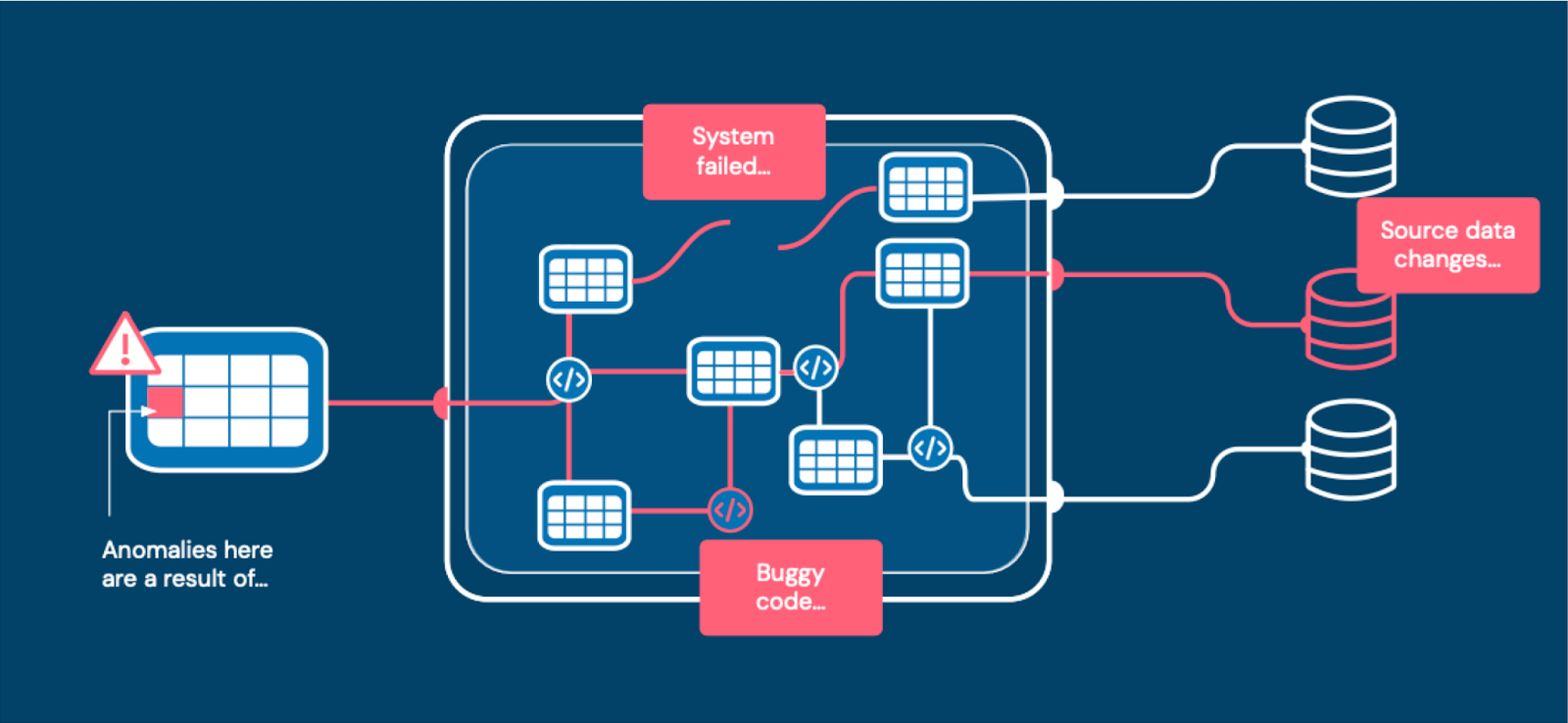
The three causes of data downtime (Image courtesy Monte Carlo)
“GenAI’s strength lies in semantic understanding,” Gavish tells BigDATAwire. “For example, it can analyze SQL query patterns to understand how fields are actually used in production, and identify logical relationships between fields (like ensuring a ‘start_date’ is always earlier than an ‘end_date). This semantic comprehension capability goes beyond what was possible with traditional ML/DL approaches.”
The new capability will make it easier for technical and non-technical employees to build data quality rules. Monte Carlo used the example of a data analyst for a professional baseball team to quickly create rules for a “pitch_history” table. There’s clearly a relationship between the column “pitch_type” (fastball, curveball, etc.) and pitch speed. With GenAI baked in, Monte Carlo can automatically recommend data quality rules that make sense based on the history of the relationship between those two columns, i.e. “fastball” should have pitch speeds of greater than 80mph, the company says.
As Monte Carlo’s example shows, there are intricate relationships buried in data that traditional ML models would have a hard time teasing out. By leaning on the human-like comprehension skills of an LLM, Monte Carlo can start to dip into those hard-to-find data relationships to find acceptable ranges of data values, which is the real benefit that this brings.
According to Gavish, Monte Carlo is using Anthropic Claude 3.5 Sonnet/Haiku model running in AWS. To minimize hallucinations, the company implemented a hybrid approach where LLM suggestions are validated against actual sampled data before being presented to users, he says. The service is fully configurable, he says, and users can turn it off if they like.
Monte Carlo is using an LLM to automatically identify relationships between data fields that humans would immediately pick up on, such as pitch type and speed (Image courtesy Monte Carlo)
Thanks to its human-like capability to grasp semantic meaning and generate accurate responses, GenAI tech has the potential to transform many data management tasks that are highly reliant on human perception, including data quality management and observability. However, it hasn’t always been clear exactly how it will all come together. Monte Carlo has talked in the past about how its data observability software can help ensure that GenAI applications, including the retrieval-augmented generation (RAG) workflows, are fed with high-quality data. With this week’s announcement, the company has shown that GenAI can play a role in the data observability process itself.
“We saw an opportunity to combine a real customer need with new and exciting generative AI technology, to provide a way for them to quickly build, deploy, and operationalize data quality rules that will ultimately bolster the reliability of their most important data and AI products,” Monte Carlo CEO and Co-founder Barr Moses said in a press release.
Monte Carlo made a couple of other enhancements to its data observability platform during its IMACT 2024 Data Observability Summit, which it held this week. For starters, it launched a new Data Operations Dashboard designed to help customers track their data quality initiatives. According to Gavish, the new dashboard provides a centralized view into various data observability from a single pane of glass.![]()
“Data Operations Dashboard gives data teams scannable data about where incidents are happening, how long they’re persisting, and how well incidents owners are doing at managing the incidents in their own purview,” Gavish says. “Leveraging the dashboard allows data leaders to do things like identify incident hotspots, lapses in process adoption, areas within the team where incident management standards aren’t being met, and other areas of operational improvement.”
Monte Carlo also bolstered its support for major cloud platforms, including Microsoft Azure Data Factory, Informatica, and Databricks Workflows. While the company could detect issues with data pipelines running in these (and other) cloud platforms before, it now has full visibility into pipeline failures, lineage and pipeline performance running on those vendors’ systems, Gavish says, including
“These data pipelines, and the integrations between them, can fail resulting in a cascading deluge of data quality issues,” he tells us. “Data engineers get overwhelmed by alerts across multiple tools, struggle to associate pipelines with the data tables they impact, and have no visibility into how pipeline failures create data anomalies. With Monte Carlo’s end-to-end data observability platform, data teams can now get full visibility into how each Azure Data Factory, Informatica or Databricks Workflows job interacts with downstream assets such as tables, dashboards, and reports.”
Related Items:
Monte Carlo Detects Data-Breaking Code Changes
GenAI Doesn’t Need Bigger LLMs. It Needs Better Data
Data Quality Is Getting Worse, Monte Carlo Says
The post Monte Carlo Brings GenAI to Data Observability appeared first on BigDATAwire.













0 Commentaires