A startup called PuppyGraph is turning heads in the big data world with a novel concept: Marrying the data storage efficiency of the data lakehouse with the analytic capabilities of a graph database. The result is a distributed, column-oriented OLAP graph query engine that runs atop Iceberg or Parquet tables in an object store and can scale horizontally into the petabyte range.
PuppyGraph was co-founded in 2023 by software engineer Weimo Liu, who cut his teeth on distributed graph databases during the early days of TigerGraph before joining Google. Liu, who is CEO of the company, understands the benefits that the graph approach holds, but has been frustrated with low adoption rates.
“A lot of users showed strong interest in graph, but most of them finally end in nothing,” Liu says. “It’s never in production. And people got tired after they spend a lot of time on it, and I think there must be something wrong.”
Graph databases are well-known to hold a big performance advantage over relational databases when it comes to executing certain types of queries across connected data. A graph database can efficiently execute a multi-hop traverse to discover that a given transaction is connected to a fraudster, for example, whereas the same workload would require a massive SQL join that would bring a relational database to its knees.
But graph databases have a fundamental limitation in their design: The data must be ETL’d into the database before the graph engine can do its thing. There is downtime associated with extracting the data from its source, transforming it into the graph database format, and then loading it into the graph database. This has been the Achille’s Heal of graph databases used for analytics (although it’s not as limiting for OTLP workloads).
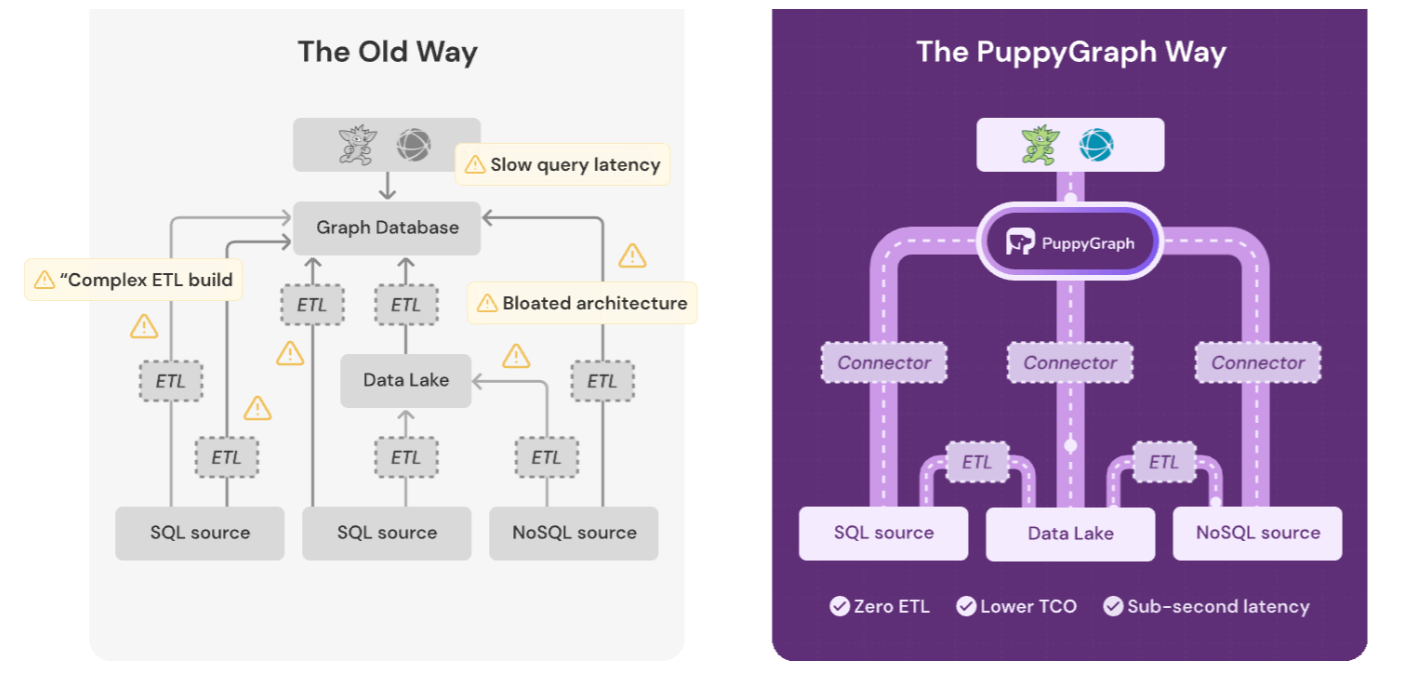
PuppyGraph is a column-oriented graph query engine for data lakehouses (Image courtesy PuppyGraph)
“I think a big blocker for the graph database adoption is not a graph–it’s about the database,” Liu says. “Loading the data from somewhere else to graph database. That is a big problem.”
While at Google, Liu was impressed with the F1 query engine team. A key element of F1 is a data model that supports table columns with structured data types. According to Liu, this works as a universal data structure that allows various data formats to be defined as a table that’s amendable to SQL queries.
“This is a very inspiring design,” Liu tells BigDATAwire. “I think if a graph can [use] the design, it will benefit much more.”
With PuppyGraph, Liu and his co-founders are hoping to eliminate that limitation in the graph database design. By separating the compute and storage layers and building a vectorized and column-oriented graph query engine, PuppyGraph says it can delivery fast OLAP graph performance on massive data sitting in object store, thereby eliminating the downtime associated with loading data into graph databases.
Just as Trino and Presto have separated the storage from the SQL query engine and helped to drive the growth of the lakehouse architecture, PuppyGraph hopes to separate the storage from the graph query engine and take advantage of data lakehouses filled with data stored in open table formats, such as Apache Iceberg.
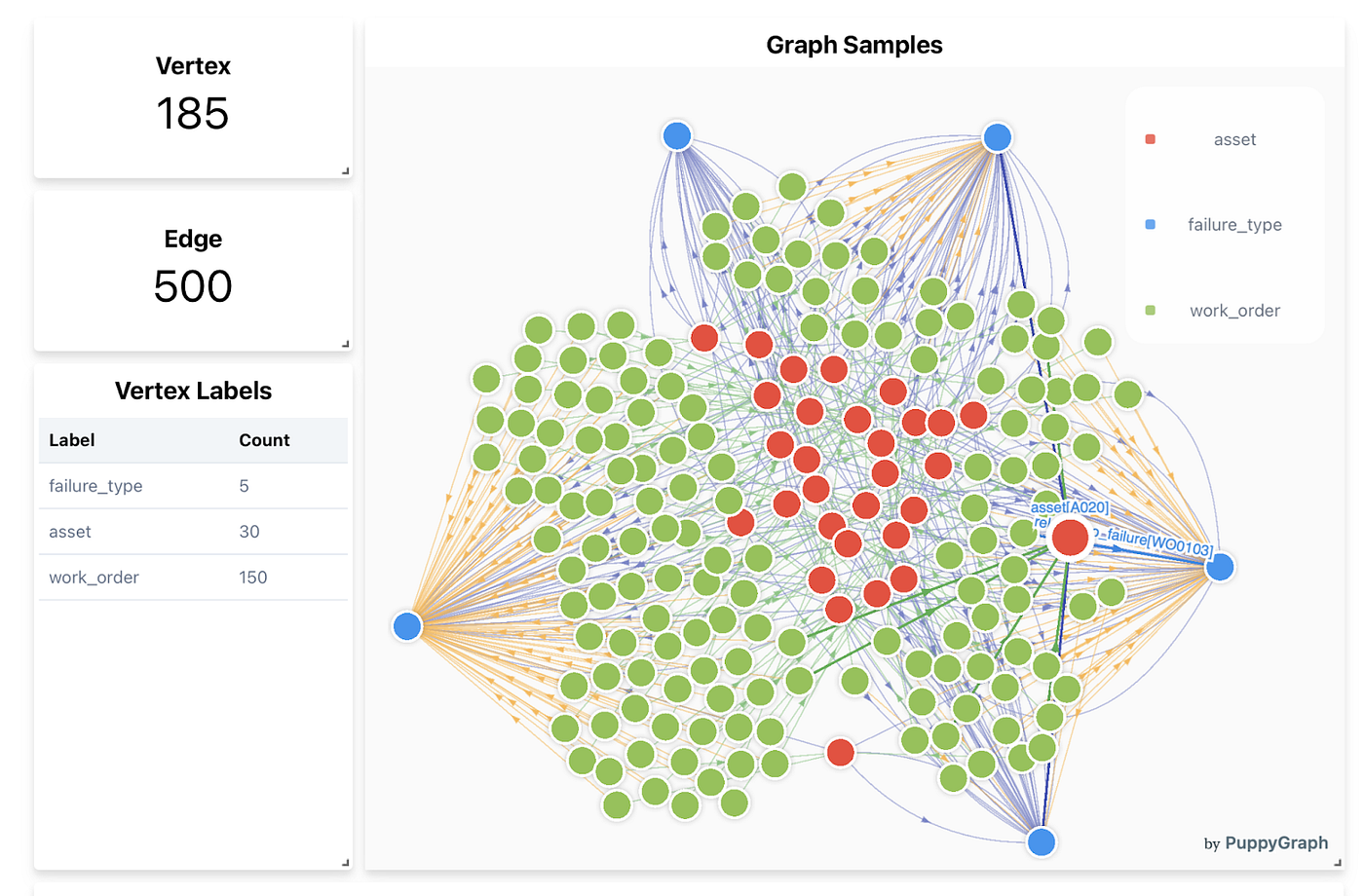
PuppyGraph executes graph queries on data stored in lakehouses (Image courtesy PuppyGraph)
“If you already have data somewhere else, like a Parquet file, or in PostgreSQL, MySQL, or Iceberg, we can just directly query on top of it to run a graph query. Then the onboard cost will be almost zero,” Liu says. “And at the same time, it solves the scalability issue, because data lakes like Iceberg and Delta Lake almost don’t have any limitation on data size. So we can leverage their storage and then answer the query, which was written in graph query language.”
PuppyGraph currently supports Cypher and Gremlin, the two most popular graph query languages. The company borrows from the Google F1 query engine design, which enables the query engine to map certain attributes of the source data into a logical graph layer that’s composed of nodes and edges, the key elements of the graph data model. This column-based approach allows PuppyGraph to efficiently run graph queries without having to process all of the data in each record, Liu says.
“Each node or each edge can have hundreds of attributes, but during one query, only maybe five or six will be accessed,” he says. “If we can leverage the column-based storage, we don’t need to access all the other attributes. We only need to put necessary data into the memory, and it can handle more edges and nodes at the same time, which also is a big benefit for the scalable graph analytics.”
In addition to the logical graph layer running atop columnar data models, PuppyGraph also leverages caching and indexing to make its queries run fast, Liu says. The company has also adopted SIMD processing technique to provide more parallelism. The entire PuppyGraph product runs in a Docker container atop Kubernetes, which handles resource scheduling and provides elasticity.
After he built the first PuppyGraph prototype, Liu contacted some of the founders of Tabular, the commercial outfit behind the Iceberg table format (since acquired by Databricks). The Iceberg founders were impressed that a three-hop query on Azure ran faster that dedicated graph databases, Liu says. “They realize, oh, there is a potential for other data models,” he says.![]()
PuppyGraph is a young company (dare we say it’s still a “pup?”), but it already has paying customers, including one company involved in cryptocurrency. The company, which has attracted $5 million in seed funding, is targeting OLAP graph and graph analytic use cases, such as fraud detection and regulatory compliance with its BYOC cloud offerings. A fully managed version of PuppyGraph is in the works.
While OLAP graph workloads are a good fit for PuppyGraph, the company does not plan to chase OLTP graph opportunities, Liu says. These transaction-oriented graph workloads don’t suffer from the same data loading and latency drawbacks that OLAP graph workloads do, he says.
But when it comes to graph analytics and data science graph workloads, the folks at PuppyGraph are convinced that a distributed graph query engine running in a vectorized fashion atop a data lakehouse filled with Iceberg tables may be the ticket to graph riches.
“Users want to analyze their data as a graph, and what they need is a graph, not a graph database,” he says. “We want to bring graph to their data. So that’s how we design our system.”
Related Items:
Why Young Developers Don’t Get Knowledge Graphs
Big Graph Workloads Need Big Cloud Hardware, Katana Graph Says
The post PuppyGraph Brings Graph Analytics to the Lakehouse appeared first on BigDATAwire.













0 Commentaires