Getting Deephaven’s real-time analytics system up and running will be easier thanks to a new installation technique using a standard Python library. The open source software also sports a new integration with Jupyter and a new table operation that will streamline aggregation functions.
The technology behind Deephaven Data Labs was originally developed 10 years ago to power analytics on fast-moving ticker data for a hedge fund. After seeing what it could do in finance, in 2017 CEO Pete Goddard decided to take his principal engineers and spin the tech out into its own company that could target a variety of industries.
After first selling the software as a proprietary solution, Deephaven has since pivoted to the open source business model, which has helped attract new users. Considering how quickly Python has grown, it was a natural fit to bring the Deephaven software closer to the open Python environment.
Last month, the Minneapolis-based company released a new Pip-based installation routine for the Deephaven product. According to Goddard, using the popular Pyhon installation routine should make it easier for users to get up and running with the software.
“We’re really focused right now on the intersection of real-time data and Python, so we’ve made a lot of investments to make it easier to launch Deephaven as a Python user,” Goddard said.
While users can still download the Docker images or build the system natively from open source repositories, Goddard expects most users to choose the simplified Pip method instead. A new integration with Juypter is also likely to attract data folks who prefer the simplicity of staying in the comfy confines of the popular data science notebook.
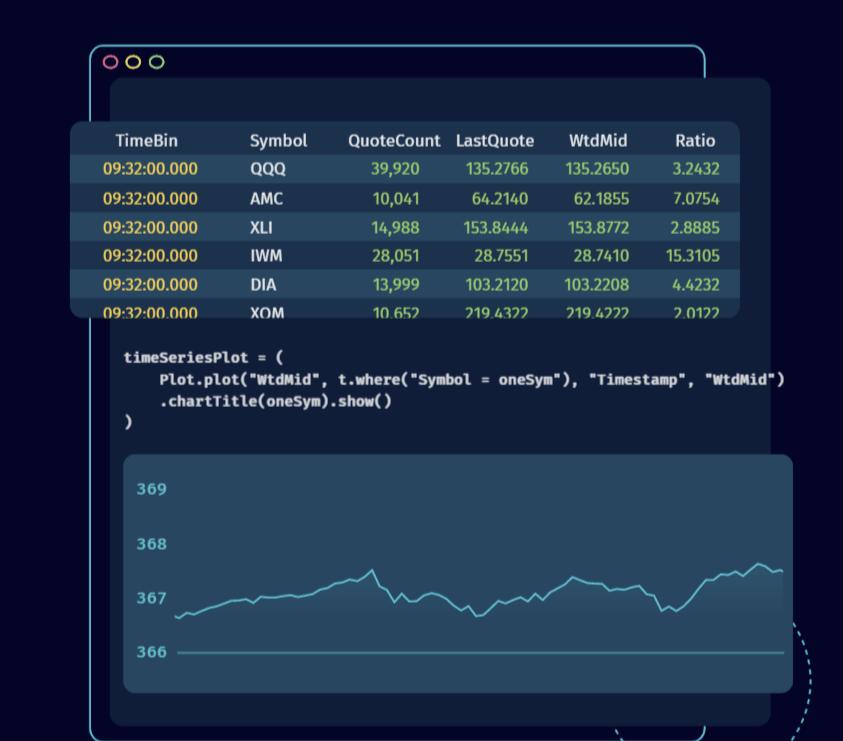
Deephaven lets users run functions against data stored in streaming tables
“We’re really focused on usability,” Goddard said. “We know people like having a nice data IDE. A lot of people like Jupyter notebooks. So we’ve done quite a bit of work to make sure all of our JavaScript widgets for real time tables…and for real time plots work natively in Jupyter.”
Deephaven already offered a browser-based front-end to go along with its data engine, which does the heavy analytical lifting on both batch and streaming data. But Goddard is excited to see what users do once they realize they can crunch real-time data, such as streams of Apache Kafka event data, using his software and the new Juypter front-end.
“We think that’s a big deal because that’s the only solution where we foresee real-time data in Jupyter notebooks,” he told Datanami. “There are a number of people who want to do that, and we’re looking forward to making it easier.”
In July, Deephaven also introduced a new table operation. Called updateBy, the new function will allow “columns to be derived from aggregations over a range of rows within a group,” the company said. That will produce an output table with the same structure and rows as the input table, but for added columns (as in update), the company said.
Goddard is confident that once users grasp the power and simplicity of the Deephaven approach and its table operation API, that they’ll want to use the software for more real time analytics and application use cases–potentially maybe even signing an enterprise software agreement.
A key advantage of Deephaven is the ability to write data processing routines that execute against both static and changing data, Goddard said. The software achieves this via the concept a streaming table. As new data arrives into the table, Deephaven performs a differential compute operation that minimizes the cycles needed to calculate the answer.
“The system is architected to think about changes in data instead of thinking about data itself,” Goddard said. “Instead of a ‘Give me a whole new table all the time,’ it can be ‘Just give me the deltas.’”![]()
Streaming data is finally emerging into the mainstream, as companies look to take advantage of shrinking windows of opportunity to take action on new data. While it’s not as well known, Deephaven is “in the same conversation” with more well-known streaming frameworks, like Spark’s Structured Streaming, Apache Flink, and Kafka Streams, Goddard said.
A proper streaming data system can do things that databases aren’t really designed to do, Goddard said. For starters, the ACID transactions typically associated with a database is just overkill. Also, SQL often doesn’t fit well with the real-time use cases.
“SQL is great. Love it. It’s a great vehicle and tool for interacting with data. But there is evidence that other models also add value,” Goddard said. “From our perspective, our table API, our operations are really very nice to work with because you just write one after the other, linearly. You don’t have to try to organize things for the optimizer.”
Deephaven also lets users bring Python libraries to bear and to tap into user defined functions (UDFs), Goddard said. Users can also get data out of Deephaven using Java, C++, and Go. Hard core developer skills aren’t necessary, although users do need the ability to string operations together.
Deephaven Community Core is free to download and use. The company also offers an enterprise edition. For more information on Deephaven products, visit the company’s website at deephaven.io/.
Related Items:
From Wall Street to Main Street: Inside Deephaven’s Big Data Journey
Is Real-Time Streaming Finally Taking Off?
How Intuit Is Building AI, Analytics, and Streaming on One Lakehouse
The post Deephaven Streamlines Access to Real-Time Analytics Platform appeared first on Datanami.













0 Commentaires