Like many large companies, LinkedIn relied on the Lamba architecture to run separate batch and streaming workloads, with a form of reconciliation at the end. After implementing Apache Beam, it was able to combine batch and streaming workloads, thereby slashing its processing time by 94%, the company says.
LinkedIn is a big user of Apache Samza, a distributed stream processing engine that the company developed in-house in Scala and Java, alongside the Apache Kafka message bus. The company uses Samza to process 2 trillion messages per day, writes LinkedIn Senior Software Engineer Yuhong Cheng in a March 23 post to the company’s engineering blog.
It also is a big user of Apache Spark, the popular distributed data processing engine. LinkedIn uses Spark to run large batch jobs, including analytics, data science, machine learning, A/B batch, and metrics reporting, against petabytes of data.
Some use cases at LinkedIn required both real-time and batch capabilities. For example, it needed to standardize the process of mapping user inputs (such as job titles, skills, or educational history) into a set of pre-defined IDs that adhere to the company’s taxonomies. Once standardized, this data could be used for search indexing or running recommendation models, Cheng writes.
“Real-time computation is needed to reflect the immediate user updates,” she writes. “Meanwhile, we need periodic backfilling to redo standardization when new models are introduced.”
LinkedIn’s standardization workflow post Beam (Image courtesy LinkedIn)
LinkedIn coded both the real-time and batch workloads in Samza, utilizing the well-worn Lamba architecture. However, the company encountered numerous difficulties with this approach. For starters, the engine was not up to the task of powering the backfilling job, which needed to standardize 40,000 member profiles per second, Cheng writes. It was also proving difficult to maintain two different codebases and two different tech stacks.
“Engineers would need to be familiar with different languages and experience two learning curves,” she writes. “If there were any issues, engineers would also need to reach out to different infra teams for support.”
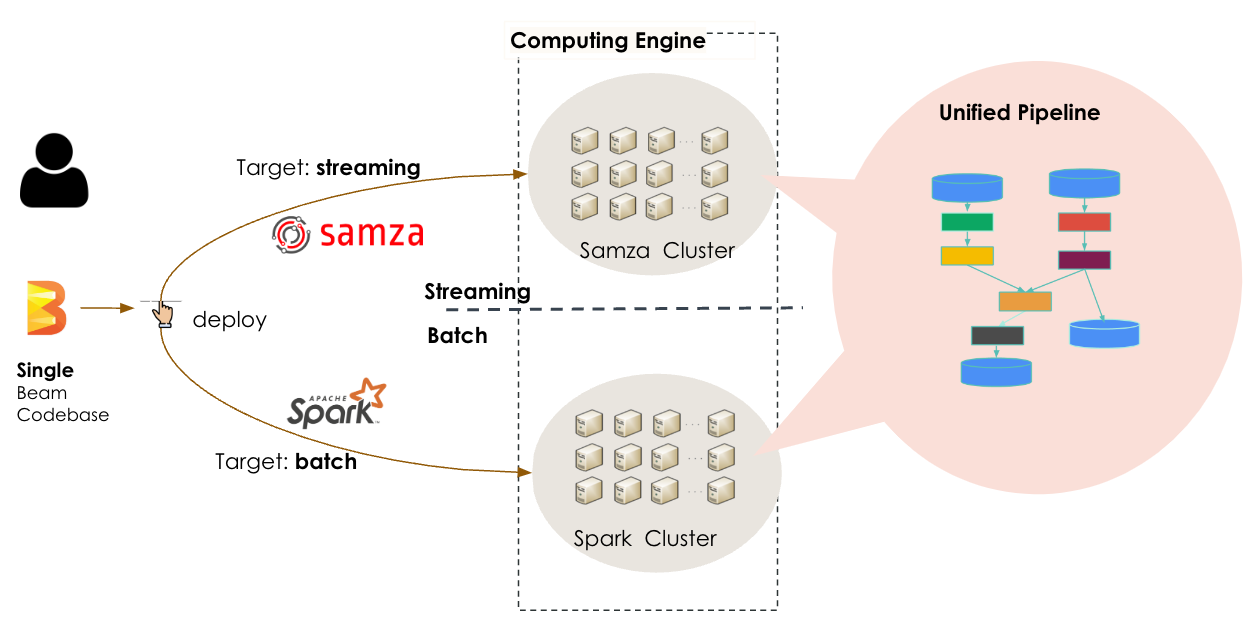
LinkedIn’s solution was to implement Apache Spark to handle the batch workload. However, instead of writing running separate Samza and Spark programs to handle these tasks, the company elected to use Samza and Spark “runners” operating within the Apache Beam framework, Cheng writes.
Apache Beam is a programming and runtime framework developed by Google to unified batch and streaming paradigms. The framework, which became a Top Level Project at the Apache Software Foundation in 2017, traces its roots back to Google’s initial MapReduce system and also reflected elements of Google Cloud Dataflow, the company’s current parallel computational paradigm.
Standardization workload processing time and resource usage before and after Beam (Image courtesy LinkedIn)
Like Google, LinkedIn has struggled to build large-scale data processing systems that can stand up under the weight of massive data sets but also withstand the technical complexity inherent in these systems. Since it was released, Beam has offered the potential to be a simplifying agent for both the development and the runtime.
“Developers only need to develop and maintain a single codebase written in Beam,” she writes. “If the target processing is a real-time one, the job is deployed through Samza Cluster as a streaming job. If the target processing is a backfilling job, the job is deployed through Spark Cluster as a batch job. This unified streaming and batch architecture enables our team to take advantage of both computing engines while minimizing development and maintenance efforts.”
The company is realizing substantial gains in compute performance as a result of the move to Apache Beam. Cheng writes:
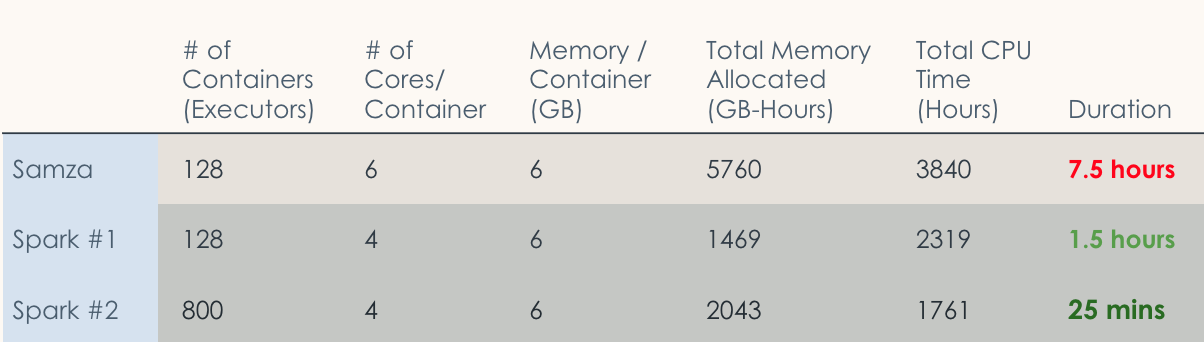
“When we ran backfilling as a streaming job, the total memory allocated was over 5,000 GB-Hours and the total CPU time was nearly 4,000 hours. After migrating to a Beam unified pipeline, running the same logic as a batch job, the memory allocated and CPU time both were cut in half. The duration also dropped significantly when we ran backfilling using Beam unified pipelines – from seven hours to 25 minutes.”
All told, the compute time was reduced by 94%-a whopping 20x improvement. Because the Spark batch environment is bigger, the total resource usage dropped only 50%, according to LinkedIn.
LinkedIn is encouraged by Beam’s efficiency and plans to use it in the future as it moves to an “end-to-end convergence” of batch and streaming workloads. The company is now looking to tackle some of the challenges that exist when working in streaming (Kafka) and batch (HDFS) environments.
Related Items:
Google/ASF Tackle Big Computing Trade-Offs with Apache Beam 2.0
Apache Beam’s Ambitious Goal: Unify Big Data Development
Google Lauds Outside Influence on Apache Beam
The post Apache Beam Cuts Processing Time 94% for LinkedIn appeared first on Datanami.












0 Commentaires