GPUs have an insatiable desire for data, and keeping those processors fed can be a challenge. That’s one of the big reasons that WEKA launched a new line of data storage appliances last week that can move data at up to 18 million IOPS and serve 720 GB of data per second.
The latest GPUs from Nvidia can ingest data from memory at incredible speeds, up to 2 TB of data per second for the A100 and 3.35 TB per second for the H100. This sort of memory bandwidth, using the latest HBM3 standard, is needed to train the largest large language models (LLMs) and run other scientific workloads.
Keeping the PCI busses saturated with data is critical for utilizing the full capacity of the GPUs, and that requires a data storage infrastructure that’s capable of keeping up. The folks at WEKA say they have done that with the new WEKApod line of data storage appliances it launched last week.
The company is offering two versions of the WEKApod, including the Prime and the Nitro. Both families start with clusters of eight rack-based servers and around half a petabyte of data, and can scale to support hundreds of servers and multiple petabytes of data.
The Prime line of WEKApods is based on PCIe Gen4 technology and 200Gb Ethernet or Infiniband connectors. It starts out with 3.6 million IOPS and 120 GB per second of read throughput, and goes up to 12 million IOPS and 320 GB of read throughput.
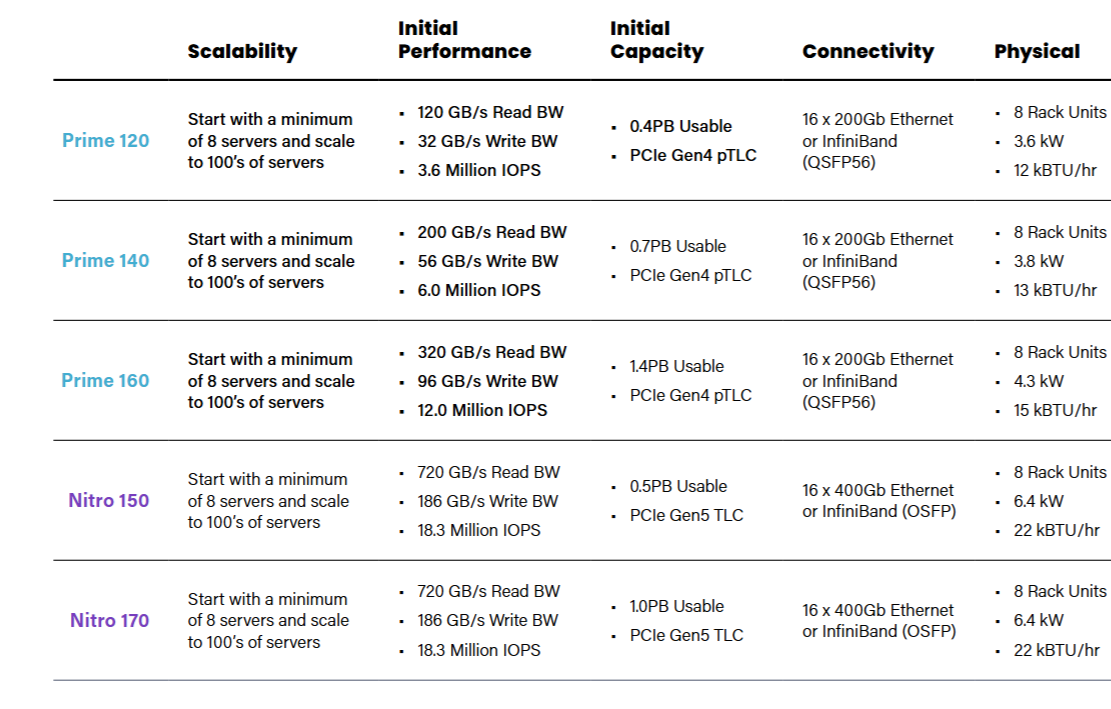
WEKApod specifications
The Nitro line is based on PCIe Gen5 technology and 400Gb Ethernet or Infiniband connectors. Both the Nitro 150 and the Nitro 180 are rated at 18 million IOPS of bandwidth and can hit data read speeds of 720 GB per second and data write speeds of 186 GB per second.
Enterprise AI workloads require high performance for both reading and writing of data, says Colin Gallagher, vice president of product marketing for WEKA.
“Several of our competitors have lately been claiming to be the best data infrastructure for AI,” Gallagher says in a video on the WEKA website. “But to do so they selectively quote a single number, often one for reading data, and leave others out. For modern AI workloads, one performance data number is misleading.”
That’s because, in AI data pipelines, there’s a necessary data interplay between reading and writing of data as the AI workloads change, he says.
“Initially, data is ingested from various sources for training, loaded to memory, preprocessed and written back out,” Gallagher says. “During training, it is continually read to update model parameters, checkpoints of various sizes are saved, and results are written for evaluation. After training, the model generates outputs which are written for further analysis or use.”
The WEKAPods utilize the WekaFS file system, the company’s high-speed parallel file system, which supports a variety of protocols. The appliances support GPUDirect Storage (GDS), an RDMA-based protocol developed by Nvidia, to improve bandwidth and reduce latency between the server NIC and GPU memory.
WekaFS has full support for GDS and has been validated by Nvidia including a reference architecture, WEKA says. WEKApod Nitro also is certified for Nvidia DGX SuperPOD.
WEKA says its new appliances include an array of enterprise features, such as support for multiple protocols (FS, SMB, S3, POSIX, GDS, and CSI); encryption; backup/recovery; snapshotting; and data protection mechanisms.
For data protection specifically, it says it uses a patented distributed data protection coding scheme to guard against data loss caused by server failures. The company says it delivers the scalability and durability of erasure coding, “but without the performance penalty.”
“Accelerated adoption of generative AI applications and multi-modal retrieval-augmented generation has permeated the enterprise faster than anyone could have predicted, driving the need for affordable, highly-performant and flexible data infrastructure solutions that deliver extremely low latency, drastically reduce the cost per tokens generated and can scale to meet the current and future needs of organizations as their AI initiatives evolve,” WEKA Chief Product Officer Nilesh Patel said in a press release. “WEKApod Nitro and WEKApod Prime offer unparalleled flexibility and choice while delivering exceptional performance, energy efficiency, and value to accelerate their AI projects anywhere and everywhere they need them to run.”
Related Items:
Legacy Data Architectures Holding GenAI Back, WEKA Report Finds
Hyperion To Provide a Peek at Storage, File System Usage with Global Site Survey
Object and File Storage Have Merged, But Product Differences Remain, Gartner Says
The post WEKA Keeps GPUs Fed with Speedy New Appliances appeared first on BigDATAwire.













0 Commentaires