The launch of ChatGPT in November 2022 was a watershed moment in natural language processing (NLP), as it showcased the startling effectiveness of the transformer architecture for understanding and generating textual data. Now we’re seeing something similar happening in the field of computer vision with the rise of pre-trained large vision models. But when will these models gain widespread acceptance for visual data?
Since around 2010, the state-of-the-art when it came to computer vision was the convolutional neural network (CNN), which is a type of deep learning architecture modeled after how neurons interact in biological brains. CNN frameworks, such as ResNet, powered computer vision tasks such as image recognition and classification, and found some use in industry.
Over the past decade or so, another class of models, known as diffusion models, have gained traction in computer vision circles. Diffusion models are a type of generative neural network that use a diffusion process to model the distribution of data, which can then be used to generate data in a similar manner. Popular diffusion models include Stable Diffusion, an open image generation model pre-trained on 2.3 billion English-captioned images from the internet, which is able to generate images based on text input.
Needed Attention
A major architectural shift occurred in 2017, when Google first proposed the transformer architecture with its paper “Attention Is All You Need.” The transformer architecture is based on a fundamentally different approach. It dispenses the convolutions and recurrence CNNs and in recurrent neural networks RNNs (used primarily for NLP) and relies entirely on something called the attention mechanism, whereby the relative importance of each component in a sequence is calculated relative to the other components in a sequence.

A neural net (Pdusit/Shutterstock)
This approach proved useful in NLP use cases, where it was first applied by the Google researchers, and it led directly to the creation of large language models (LLMs), such as OpenAI’s Generative Pre-trained Tranformer (GPT), which ignited the field of generative AI. But it turns out that the core element of the transformer architecture–the attention mechanism–isn’t restricted to NLP. Just as words can be encoded into tokens and measured for relative importance through the attention mechanism, pixels in an image can also be encoded into tokens and their relative value calculated.
Tinkering with transformers for computer vision started in 2019, when researchers first proposed using the transformer architecture for computer vision tasks. Since then, computer vision researchers have been improving the field of LVMs. Google itself has open sourced ViT, a vision transformer model, while Meta has DINOv2. OpenAI has also developed transformer-based LVMs, such as CLIP, and has also included image-generation with its GPT-4v. LandingAI, which was founded by Google Brain co-founder Andrew Ng, also uses LVMs for industrial use cases. Multi-modal models that can handle both text and image input–and generate both text and vision output–are available from several providers.
Transformer-based LVMs have advantages and disadvantages compared to other computer vision models, including diffusion models and traditional CNNs. On the downside, LVMs are more data hungry than CNNs. If you don’t have a significant number of images to train on (LandingAI recommends a minimum of 100,000 unlabeled images), then it may not be for you.
On the other hand, the attention mechanism gives LVMs a fundamental advantage over CNNs: they have a global context baked in from the very beginning, leading to higher accuracy rates. Instead of trying to identify an image starting with a single pixel and zooming out, as a CNN works, an LVM “slowly brings the whole fuzzy image into focus,” writes Stephen Ornes in a Quanta Magazine article.
In short, the availability of pre-trained LVMs that provide very good performance out-of-the-box with no manual training has the potential to be just as disruptive for computer vision as pre-trained LLMs have for NLP workloads.
LVMs on the Cusp
The rise of LVMs is exciting folks like Srinivas Kuppa, the chief strategy and product officer for SymphonyAI, a longtime provider of AI solutions for a variety of industries.
According to Kuppa, we’re on the cusp of big changes in the computer vision market, thanks to LVMs. “We are starting to see that the large vision models are really coming in the way the large language models have come in,” Kuppa said.
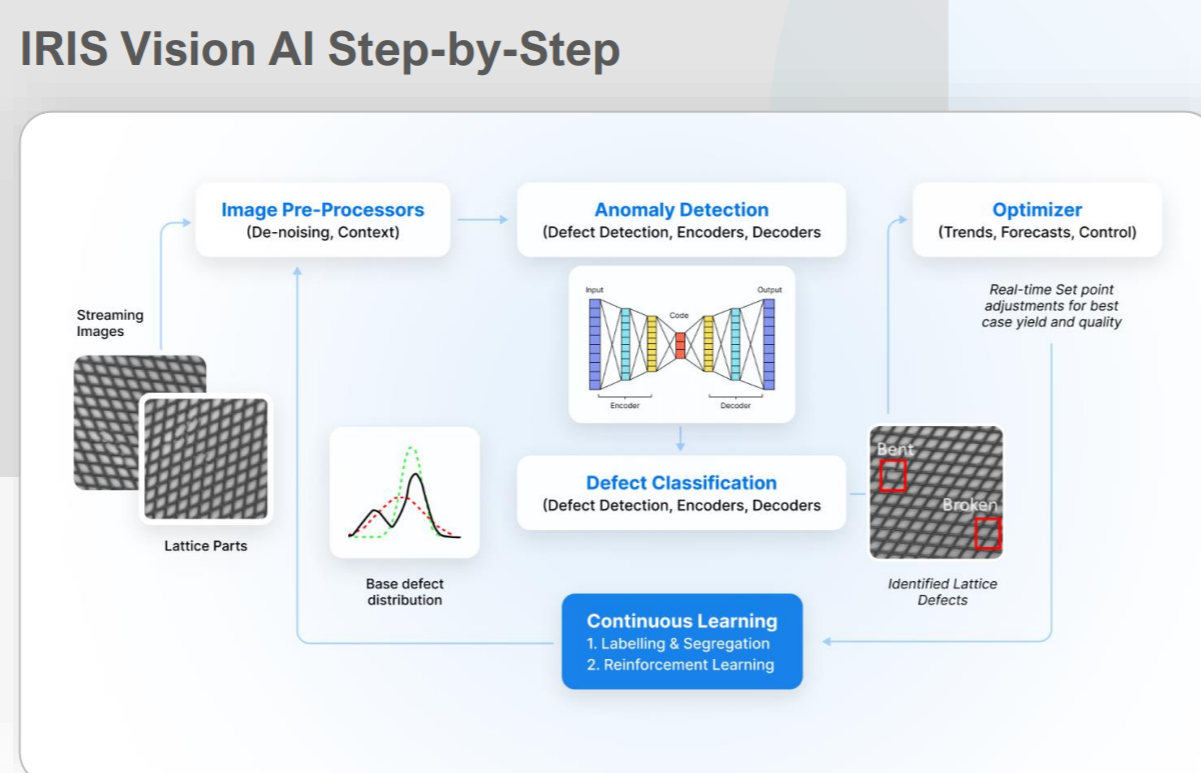
SymphonyAI’s Iris software helps implement LVMs for customers (Image courtesy SymphonyAI)
The big advantage with the LVMs is that they are already (mostly) trained, eliminating the need for customers to start from scratch with model training, he said.
“The beauty of these large vision models, similar to large language models, is it’s pre-trained to a larger extent,” Kuppa told BigDATAwire. “The biggest challenge for AI in general and certainly for vision models is once you get to the customer, you’ve got to get a whole lot of data from the customer to train the model.”
SymphonyAI uses a variety of open source LVMs in customer engagements across manufacturing, security, and retail settings, most of which are open source and available on Huggingface. It uses Pixel, a 12-billion parameter model from Mistral, as well as LLaVA, an open source multi-modal model.
While pre-trained LVMs work well out of the box across a variety of use cases, SymphonyAI typically fine-tune the models using its own proprietary image data, which improves the performance for customers’ specific use case.
“We take that foundation model and we fine tune it further before we hand it over to a customer,” Kuppa said. “So once we optimize that version of it, when it goes to our customers, that is multiple times better. And it improves the time to value for the customer [so they don’t] have to work with their own images, label them, and worry about them before they start using it.”
For example, SymphonyAI’s long record of serving the discrete manufacturing space has enabled it to obtain many images of common pieces of equipment, such as boilers. The company is able to fine-tune LVMs using these images. The model is then deployed as part of its Iris offering to recognize when the equipment is damaged or when maintenance has not been completed.
“We are put together by a whole lot of acquisitions that have gone back as far as 50 or 60 years,” Kuppa said of SymphonyAI, which itself was officially founded in 2017 and is backed with a $1 billion investment by Romesh Wadhwani, an Indian-American businessman. “So over time, we have accumulated a lot of data the right way. What we did since generative AI exploded is to look at what kind of data we have and then anonymize the data to the extent possible, and then use that as a basis to train this model.”
LVMs In Action
SymphonyAI has developed LVMs for one of the largest food manufacturers in the world. It’s also working with distributors and retailers to implement LVMs to enable autonomous vehicles in warehouse and optimize product placement on the shelves, he said.
“My hope is that the large vision models will start catching attention and see accelerated growth,” Kuppa said. “I see enough models being available on Huggingface. I’ve seen some models that are available out there as open source that we can leverage. But I think there is an opportunity to grow [the use] quite significantly.”

(Fotogrin/Shutterstock)
One of the limiting factors of LVMs (besides needing to fine-tune them for specific use cases) is the hardware requirements. LVMs have billions of parameters, whereas CNNs like ResNet typically have only millions of parameters. That puts pressure on the local hardware needed to run LVMs for inference.
For real-time decision-making, an LVM will require a considerable amount of processing resources. In many cases, it will require connections to the cloud. The availability of different processor types, including FPGAs, could help, Kuppa said, but it’s a current need nonetheless.
While the use of LVMs is not great at the moment, its footprint is growing. The number of pilots and proofs of concepts (POCs) has grown considerably over the past two years, and the opportunity is substantial.
“The time to value has been shrunk thanks to the pre-trained model, so they can really start seeing the value of it and its outcome much faster without much investment upfront,” Kuppa said. “There are a lot more POCs and pilots happening. But whether that translates into a more enterprise level adoption at scale, we need to still see how that goes.”
Related Items:
The Key to Computer Vision-Driven AI Is a Robust Data Infrastructure
Patterns of Progress: Andrew Ng Eyes a Revolution in Computer Vision
AI Can See. Can We Teach It To Feel?
The post When Will Large Vision Models Have Their ChatGPT Moment? appeared first on BigDATAwire.












0 Commentaires