The IT industry loves its stacks. First there was the LAMP stack, then the Hadoop stack became popular. Over the past five years, something called the Modern Data Stack has taken hold in our collective data psyche, and now there are rumblings of something called the Compsable Data Stack. But is the stack concept still useful for big data and analytics?
IT stacks grew out of the desire to do as little integration work as possible in assembling production systems, usually from open source parts. You could download the pieces in the original LAMP stack–which included an operating system (Linux), a Web server (Apache), a database (MySQL), and a programming language (PHP, or even Python or Perl)–and hook them together to serve Web apps in 2005 without doling out a seven-figure contract to Accenture or another SI.
By 2010, the Hadoop age was ushering in another exercise in stacks. Initially built on the combination of a distributed file system (HDFS) and a computing framework (MapReduce), the Hadoop stack grew and grew, eventually morphing into a collection of about two dozen different projects (Hive, Spark, HBase, etc. etc. etc.).
While it sounded great in theory, the practicality of keeping the asparagus charts up-to-date–let alone maintaining compatibility amongst dozens of constantly evolving open source projects– proved too much for the likes of Hortonworks and Cloudera to bear, and the big yellow elephant and its associated stack came tumbling down.
Rise of MDS
While the Hadoop business model officially died in 2019, many Hadoop components (Spark, Presto, Kafka, Hive, and even HDFS) continue to live happy and productive lives elsewhere. And by elsewhere, I mean the cloud, which brings us to the Modern Data Stack, or MDS for short.
The MDS started taking root around the same time the cloud bigs started gobbling up big data workloads. Instead of trying to run your own stack of integrated Hadoopery, public cloud vendors like AWS provided customers with shrink-wrapped data services, such as Glue for ETL, RedShift for SQL data analytics, or Elastic MapReduce (EMR) for traditional Hadoop workloads. Google Cloud had its own stack, based around BigQuery, as did Snowflake, Microsoft, and eventually Databricks. There weren’t as many deployment options or knobs to turn, but that ended up being a good thing, as customer adoption soared.

A Hortonworks asparagus chart, circa 2014
Today, the cloud is an indispensable ingredient of the MDS. It is just assumed that if you have an MDS, that you are running the components in the modern cloud fashion, which means separating compute from storage and enabling infinite scalability via containers and serverless technologies and techniques. The tools that surround the MDS and interoperate with it, therefore, must also adhere to this new cloud era, as opposed to the old era of on-prem compute and storage.
One of the proponents of the MDS is Alation, a provider of data catalogs and governance tools. According to a 2023 blog post, the MDS is composed of a data warehouse, an ETL tool, data ingestion and integration services, reverse ETL, data orchestration, and business intelligence tools. “A modern data stack is typically more scalable, flexible, and efficient than a legacy data stack,” Alation says in its blog. “A modern data stack relies on cloud computing, whereas a legacy data stack stores data on servers instead of in the cloud.”
MongoDB is another proponent of the MDS. Like Alation, MongoDB takes the phrase to refer to pre-integrated combinations of software running on the cloud. It sees itself it several big data stacks, including MEAN, which includes MongoDB, Express, Angular, and Node; MERN, which includes MongoDB, Express, React.js, and Node; and MEVN, which includes MongoDB, Express, Vue.js, and Node.
Stacks Beget Stacks
InfluxData, which develops a time-series database, is betting the future of InfluxDB on the FDAP stack. What’s the FDAP stack? Glad you asked!
According to InfluxData (which coined the term), FDAP refers to the combination of several Apache Arrow projects, including Flight (a network protocol), DataFusion (a query engine), and Arrow itself (in-memory columnar data format), along with Parquet (disk-based columnar data format). (Stay tuned to Datanami for a story on InfluxDB 3.0, which is built on FDAP.)
The Arrow ecosystem is growing quickly at the moment, and so it makes some sense for big data developers to build around it as the core of a larger stack.
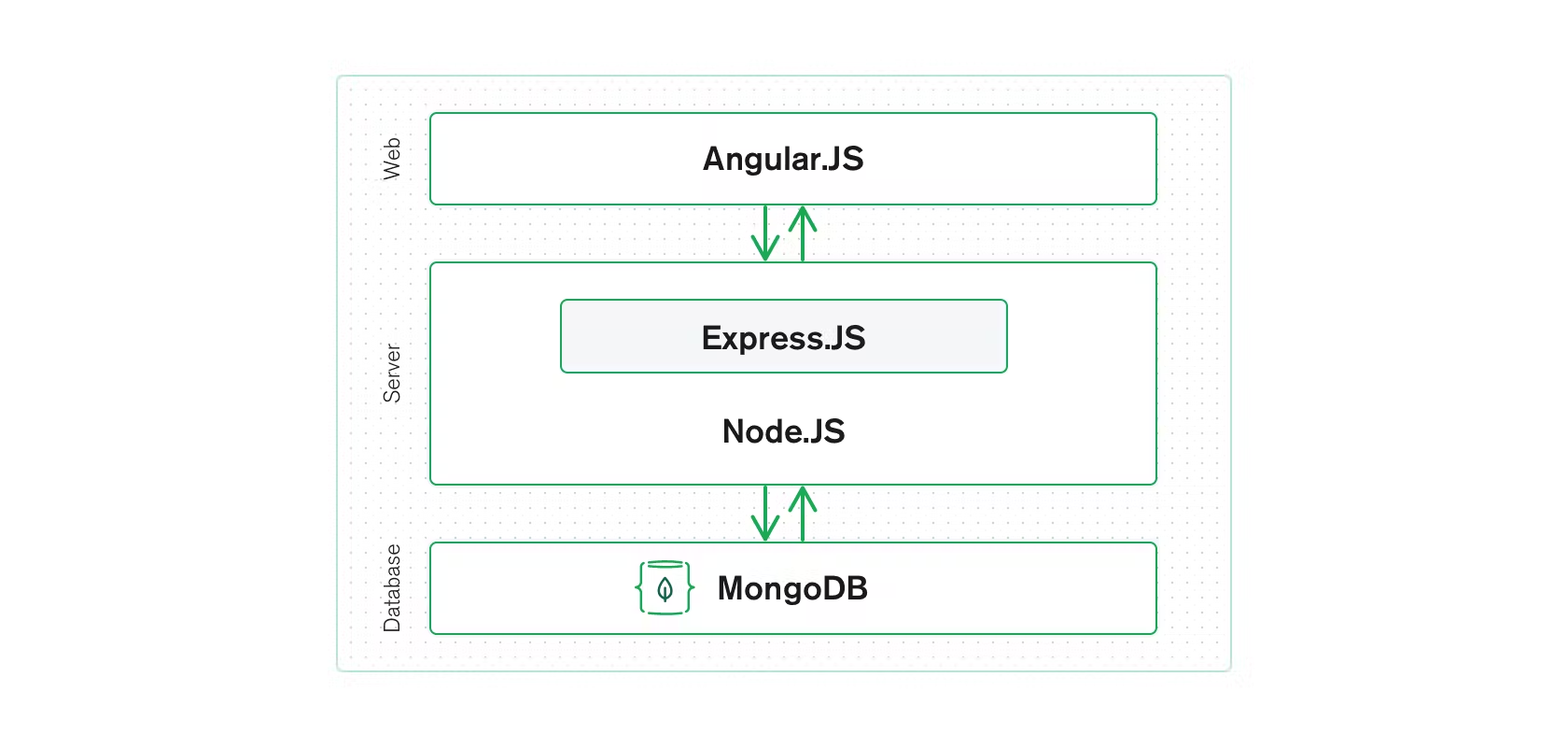
MongoDB’s MEAN stack
Wes McKinney, the creator of Pandas and one of the creators of Arrow, recently co-authored a paper discussing these topics. Titled “The Composable Data Management System Manifesto,” the paper bemoans the rise of hundreds of data management systems, each creating a monolithic silo of data that hinders integration and progress. The solution, as you might guess, is something they call a “composable data management system.”
“…[C]onsidering the recent popularity of open source projects aimed at standardizing different aspects of the data stack, we advocate for a paradigm shift in how data management systems are designed,” write McKinney, et al. “We believe that by decomposing these into a modular stack of reusable components, development can be streamlined while creating a more consistent experience for users.”
The Composable Data Stack, as McKinney call it, builds around popular open source components like Arrow, ORC, Parquet, Hudi, and Iceberg data formats; Velox and DuckDB columnar query processing; Apache Calcite and Orca for query optimizers; and Ibis, Spark, Ray, and even good old MapReduce execution frameworks.
“Despite sharing many of the same architectural decisions, data structures, and internal data processing techniques, today, the degree of reuse between these systems is unsettlingly limited,” the authors of the paper write. “We believe that by componentizing data management systems, the pace of innovation can be accelerated.”
We’re All MDS Now
But not everyone agrees that the MDS stack is even needed anymore. According to Tristan Handy, the co-founder and CEO of dbt Labs, the idea of an all-encompassing stack for big data is now unneccessary.
In a recent blog post, Handy shared his thoughts on why we may be living in a post-data-stack universe.
“When I was a consultant, helping small companies build analytics capabilities, I would only work with MDS tooling. It was so much better that I simply wouldn’t take on a project if the client wanted to use pre-cloud tools,” he wrote. The term actually conveyed important information…that has now outlived its usefulness.”
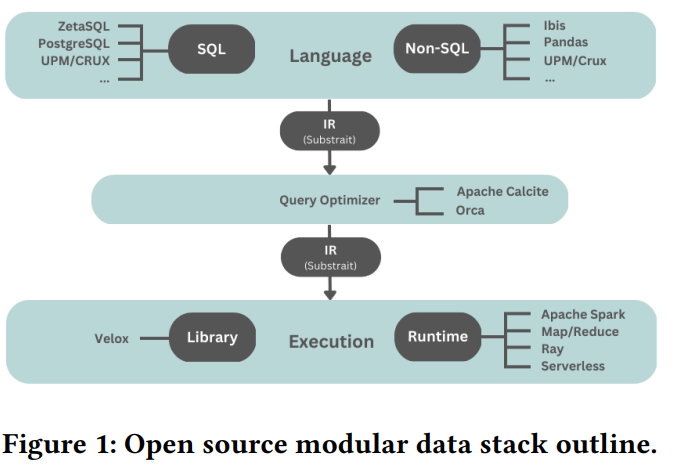
The Composable Data Stack (Courtesy: “The Composable Data Management System Manifesto”)
The data situation on the ground has changed dramatically, and today, most data products are built for the cloud already, Handy wrote. “Either they have been built in the past 10 years and therefore baked in cloud-first assumptions, or they have been re-architected to do so,” he wrote
To make his point, Handy compared Looker and Tableau. Looker, which Google bought several years ago, was hailed as the more modern analytic toolset for working with cloud-based data warehouses, like Amazon Redshift. Tableau, which was acquired by Salesforce several years ago, was the dominant vendor from the pre-cloud era, good for working with on-prem data warehouses from the previous era.
While it’s true that Tableau did not possess the same cloud capabilities as Looker in the year 2016, the team at Tableau did the hard engineering work to gain those capabilities, thus gaining entry into the MDS club.
There are many such examples, Handy said. “I have talked to the founders of so many of these companies and ‘migrating to the cloud’ is almost always this harrowing bet-the-company march through the desert,” he writes. “But it’s so existential that everyone does it anyway (or dies trying).”
Jumping the MDS Shark
Nearly all big data tool vendors can now truthfully say they’re part of the MDS, which in a way has eliminated its usefulness as a market differentiator. That fact, as well as the deteriorating market conditions in 2023, combined to take the wind out of MDS sales.
“[C]irca 2021, the MDS had officially jumped the shark,” Handy wrote.
That’s not to say that customers haven’t benefited from having pre-integrated tools, or an MDS, if you will. According to Handy, buyer willingness to construct a stack from eight to 12 vendors has declined significantly.

dbt Labs founder and CEO Tristan Handy plans to use the phrase “analytics stack” (Photo by MHamiltonVisuals)
“Companies are much more likely today to expect to buy two to four products as the core of their analytics infrastructure,” Handy wrote. “This creates yet more pressure for consolidation, and will likely drive more M&A activity and competition across the vendor landscape.”
The backdrop to all this is the rise of AI and generative AI. While MDS and GenAI are complementary, asking potential buyers or investors to keep two ideas in their heads simultaneously is just too much, Handy said.
“The MDS was a big, important market trend,” he wrote. “But AI is bigger. A lot bigger. And it’s hard for data investors and data buyers to focus on too many trends at once.”
At the end of the day, using the MDS label is fighting the last war.
“The cloud has won; all data companies are now cloud data companies. Let’s move on,” he wrote. “Analytics is how I plan on speaking about and thinking about our industry moving forwards–not some microcosm of ‘analytics companies founded in the post-cloud era.’”
The “analytics stack” does have a nice ring to it.
Related Items:
It’s Time for the All-in-One Data Stack
In Search of the Modern Data Stack
The post Does Big Data Still Need Stacks? appeared first on Datanami.











0 Commentaires