With $274 billion in revenue last year and $3.3 trillion in assets under management, JPMorgan Chase has more resources than most to devote to building a winning data and AI strategy. But as James Massa, JPMorgan Chase’s senior executive director of software engineering and architecture, explained during his SolixEmpower keynote last week, even the biggest companies in the world must pay close attention to the data and AI details in order to succeed.
In his Solix Empower 2024 keynote address, titled “Data Quality and Data Strategy for AI, Measuring AI Value, Testing LLMs, and AI Use Cases,” Massa provided a behind-the-scenes glimpse into how the storied financial services firm handles data and AI challenges like model testing, data freshness, explainability, calculating value, and regulatory compliance.
One of the big issues in adopting large language models (LLMs) is trust, Massa said. When a company hires a new employee, they look for a degree that signifies a university has vetted his or her abilities. While LLMs, ostensibly, are designed to replace (or at least augment) human workers, we don’t have the same type of certification that says “you can trust this LLM.”
“What is the experience of the LLM employee that’s there? What kind of data they…trained upon? And are they very good?” Massa said in the Qualcomm Auditorium on the University of California, San Diego campus, where the data management software vendor Solix Technologies held the event. “That’s the thing that doesn’t exist yet for AI.”
We’re still in the early days of AI, he said, and the AI vendors, like OpenAI, are constantly tweaking their algorithms. It’s up to the AI adopters to continuously test their GenAI applications to ensure things are working as advertised, since they don’t get any guarantees from the vendors.
“It’s challenging to quantify the LLM quality and set benchmarks,” he said. “Because there’s no standard and it’s hard to quantify, we’re losing something that has been there for years.”

James Massa, JPMorgan Chase’s senior executive director of software engineering and architecture, speaking at SolixEmpower 2024 at UCSD on November 14, 2024
In the old days, the quality assurance (QA) team would stand in the way of pushing an app to production, Massa said. But thanks to the development of DevOps tools and techniques, such as Git and CICD, QA practices have become more standardized. Software quality has improved.
“We had things like expected results, full coverage of the code. We reached an understanding that if this and that happens, then you can go to production. That’s not there as much today,” Massa said. “Now we’re back to the push and the pull of whether something should go or shouldn’t go. It becomes a personality contest about who’s got more of the gravitas and weight to stand up in the meeting and say, this needs to go forward or this needs to be pulled back.”
In the old days, developers worked in a probabilstic paradigm, and software (mostly) worked in a predictable manner. But AI models are probabilistic, and there are no guarantees you’ll get the same answer twice. Companies must keep humans-in-the-loop to ensure that AI doesn’t get too far out of touch with reality.
Instead of getting a single, correct answer during QA testing, the best that AI testers can hope for is an “expected type of answer,” Massa said. “There’s no such thing as testing complete,” he said. “Now the LLMs, they’re almost practically alive. The data drifts and you get different results as a result.”
Things get even more complex when AI models interact with other AI models. “It’s like infinity squared. We don’t know what’s going to happen,” he said. “So we must decide on how much human in the loop we’re going to have to review the answers.”
JPMC uses several tools to test various aspects of LLMs, including Recall-Oriented Understudy for Gisting Evaluation ROUGE) for testing recall, BiLingual Evaluation Understudy (BLEU) for testing precision, Ragas for measuring a combination of recall, faithfulness, context relevancy, and answer relevancy, and the Elo rating system for testing how models change over time, Massa said.
Another side effect of the lack of trust in AI systems is the increased need for explainability. Massa recalled a simple rule that all software engineering managers followed.
“You explain it to me in 60 seconds. If you can’t do that, you don’t sufficiently understand it, and I don’t trust that you haven’t made a lot of bugs. I don’t trust that this thing should go to production,” Massaid said. “That was the way we operated. Explainability is a lot like that with the LLM. If you can’t explain to me why you’re getting these results and how you know you won’t get false negatives, then you can’t go to production.”

(Deemerwha studio/Shuttestock)
The amount of testing that AI will require is immense, particularly if regulators are involved. But there are limits to how much testing can be realistically done. For instance, say an AI developer has built a model and tested it thoroughly with six month’s worth of data, followed by further analysis of the test automated by a machine, Massa said. “I should be going to production on roller skates,” he told his audience. “This is great.”
But then the powers that be dropped a big word on him: Sustainability.
“I’d never heard [it] before, sustainability,” he said. “This is what sustainability says on a go forward basis. Is this sustainable? How do you know on a go-forward basis this thing won’t fall apart on you? How do you keep up with that?”
The answer, Massa was told, was to have a second LLM check the results of the first. That led Massa to wonder: Who’s checking the second LLM? “So it’s a hall of mirrors,” he said. “Just like in compliance…tthere’s first, second, third lines of compliance defense.”
If the lack of certification, QA challenges, and testing sustainability doesn’t trip you up, there is always the potential to have data problems, including stale data. Data that has been sitting in one place for a long time may no longer meet the needs of the company. That requires more testing. Anything impacting the AI product, whether it’s vector embeddings or documents used for RAG, need to be checked, he said. Often times, there will be dozens of versions of a single document, so companies also need an expiry system for deprecating old versions of documents that are more likely to contain stale data.
“It’s very simple,” Massa said. “It’s not rocket science, what needs to be done. But it takes enormous effort and money to make an app. And hopefully there’ll be more [vendor] tools that help us do it. But so far, there’s a lot of rolling your own to get it done.”
Checking for data quality issues one time won’t get you far with Massa, who advocates for a “zero trust” policy when it comes to data quality. And once a data quality issue is detected, the company must have a type of ticketing workflow system to make sure that the issues are fixed.

Data freshness is a concern at JPMC
“It’s great, for example, that you tested all the data once on the way in. But how do you know that the data hasn’t gone bad by some odd process along the way while it was sitting there?” he said. “Only if you test it before you use it. So think zero-trust data quality.”
Guardrails are also needed to keep the AI from behaving badly. These guardrails function like firewalls, in that they prevent bad things from coming into the company as well as prevent bad things from going out, Massa said. Unfortunately, it can be quite challenging to build guardrails to handle every potentiality.
“It’s very hard to come up with those guardrails when there’s infinity squared different things that could happen,” he said. “They said, so prove to me, without a shadow of a doubt, that you’ve covered infinity squared things and you have the guardrails for it.” That’s not likely to happen.
JPMC has centralized functions, but it also wants its data scientists to be free to pursue “passion projects,” Massa said. To enable this sort of data use, the company has adopted a data mesh architecture. “Data mesh is good to make the data both available and discoverable,” he said.
The company’s data strategy is a mix of bottom-up and top-down approaches, Massa said. “We’re kind of playing both ends,” he says. “They said it’s okay to have passion projects, for example, because that fosters innovation and learning, and you never know what’s going to come out when you have the centralized control.”
Some centralized control is necessary, however, such when it comes to AI regulations, compliance and sensitive data. “I think we’re doing experiments at either end of the continuum to some degree, and trying to find where we belong, where we want to be going forward,” he said. “Somewhere in the middle, as usual. Truth is always in the middle.”
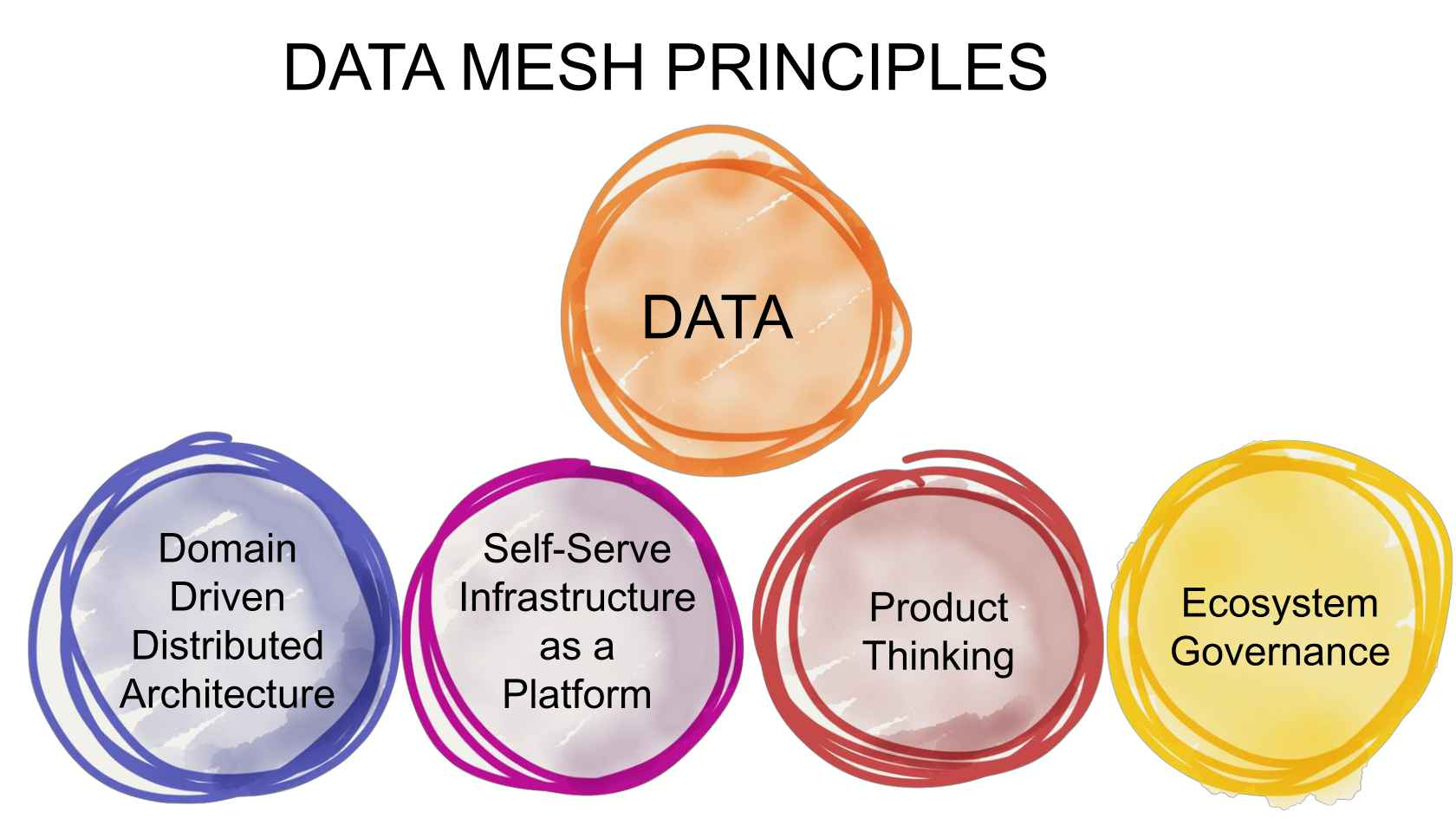
(Image courtesy Zhamak Dehghani)
At one point, Massa’s team had 300 AI models, but that number has been whittled down to about 100, he says. Part of that reduction stemmed from the company’s requirement that every model have a dollar value and generate a positive ROI.
Finding AI value is not always easy, Massa said. For some AI models, such as fraud prevention, assigning an ROI is relatively straightforward, but in other cases, it’s quite difficult. The ambiguity of regulatory compliance rules makes it difficult to assess impacts, too.
Some projects are better candidates for AI than others. Projects that can scale are better for the “AI chainsaw” than projects that can’t scale. “I’m not going to take a chainsaw to cut down that little sapling, only if there’s a giant redwood,” he said. “The AI is a chainsaw.”
Another lessons Massa learned is that people don’t scale. Projects that require constant attention from data scientists aren’t not the best candidates for ongoing investment. That’s a lesson he learned from the days of traditional machine learning.
“It only took one or two or three models before I found out that my entire team is devoted to maintaining the models,” he said. “We can’t make any new models. It doesn’t scale, because people don’t scale. So that should be taken into account as early as possible, so that you don’t end up like me.”
You can view Massa’s presentation here.
Related Items:
Solix Hosting Data and AI Conference at UCSD
Top Five Reasons Why ChatGPT is Not Ready for the Enterprise
Data Quality Is A Mess, But GenAI Can Help
The post Tips on Building a Winning Data and AI Strategy from JPMC appeared first on BigDATAwire.













0 Commentaires